Noveum AI vs Langfuse: which LLM observability platform fits your team?
An honest, detailed comparison of the leading observability tools for AI engineers focused on evaluation, monitoring, and automated remediation.
Best for automated eval at scale and for teams that want to know not just what broke, but exactly how to fix it
Best for open-source flexibility and for teams that want full control over their own observability stack
“We recently switched from Langfuse to Noveum AIfor our DarGlobal team, and the experience has been very positive. The Noveumteam helped us integrate directly into our existing codebase, which made onboarding much smoother. Compared to Langfuse, maintenance and deployment overhead dropped significantly, saving engineering effort and operational cost.
The biggest workflow improvement was AI-assisted debugging. We used to manually dig through logs, copy tracesinto Claude Code, and iterate from there. With Noveum, we analyze spans and tracesinside the platform and identify issues in place, which has saved a lot of debuggingtime. AI-based scorer recommendations also removed the guesswork of which scorers to build and configure. When we needed CrewAI, the team implemented it quickly and helped us integrate it properly. Shivam and the broader team have been responsive throughout, proactive on our feedback, and helpful in suggesting code changes when needed. Overall, the platform has streamlined our AI observability and debuggingwhile reducing operational overhead.”

Rehan Hussain Imam
Senior AI consultant, DarGlobal
Which tool is right for you?
Langfuse gives you the data. Noveum gives you the answer.
Langfuse excels when engineers want open-source building blocks and full hosting choice. Every trace, every score, every prompt version is visible and yours to act on. Noveum is built for teams that want the entire eval loop to run on its own. You connect your stack, it scores everything automatically, and when something breaks, NovaPilot identifies the issue and suggests fixes instantly without needing engineers to constantly monitor it.
In a June 2026 benchmark of eight LLM evaluation platforms (Noveum, Arize/Phoenix, Braintrust, Maxim, Galileo, Patronus, DeepEval, and Ragas), Noveum achieved a composite accuracy score of 0.999, the highest of all eight platforms tested. It also had the fastest judge latency at 0.59 seconds per call. Langfuse was not part of this benchmark. Full methodology and raw scores are published at noveum.ai.
The details that actually matter
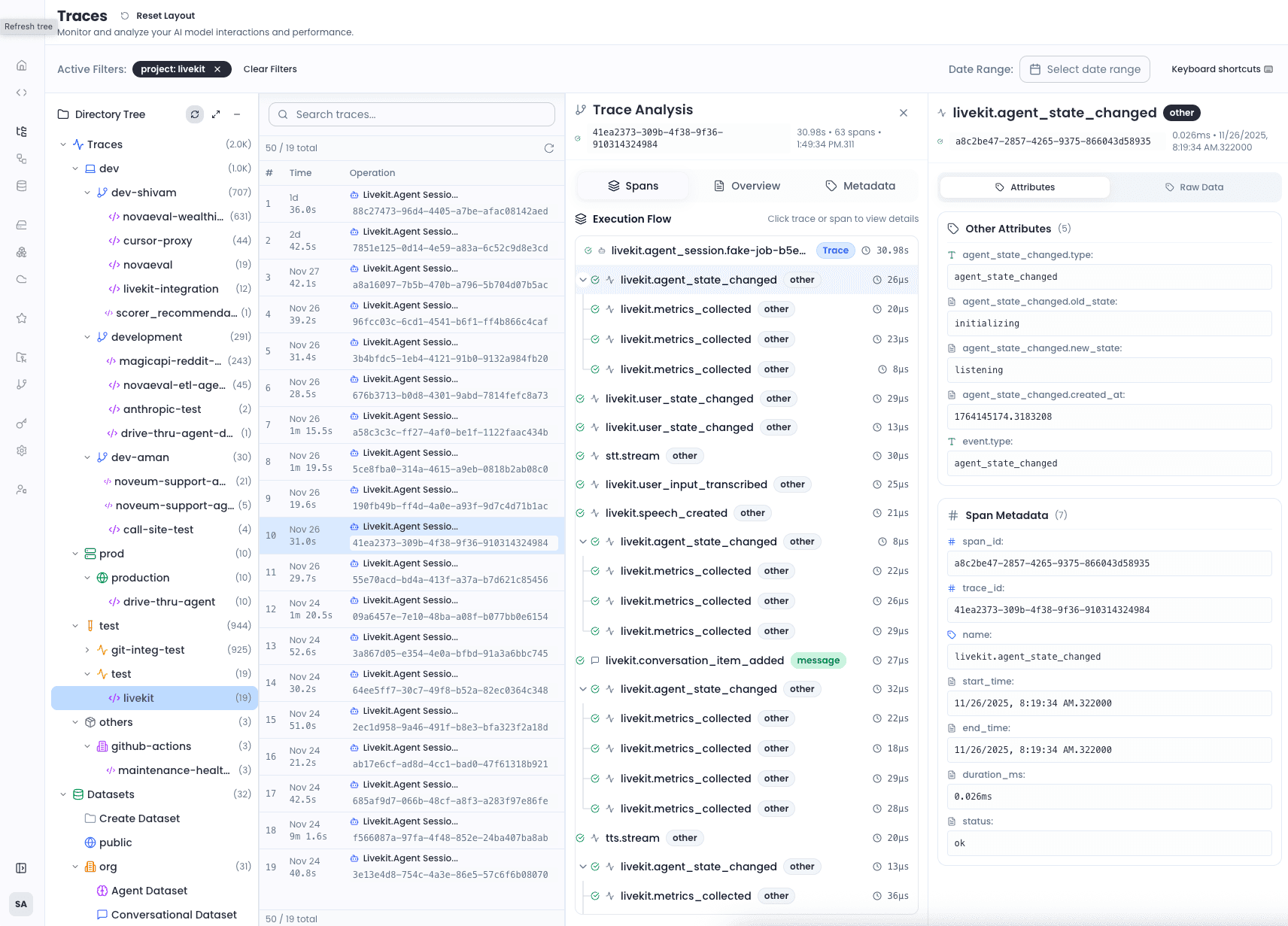
Judges built in. You stay out of the loop.
Noveum ships with 100+ built-in scorers for hallucination, faithfulness, RAG quality, and safety. In a June 2026 benchmark of eight platforms, it caught 89% of hallucinations at a 10% false-alarm rate (F1 0.84), the highest in the study. With Langfuse, you build and maintain your own LLM-as-judge pipeline before any trace gets scored.
Learn about scorers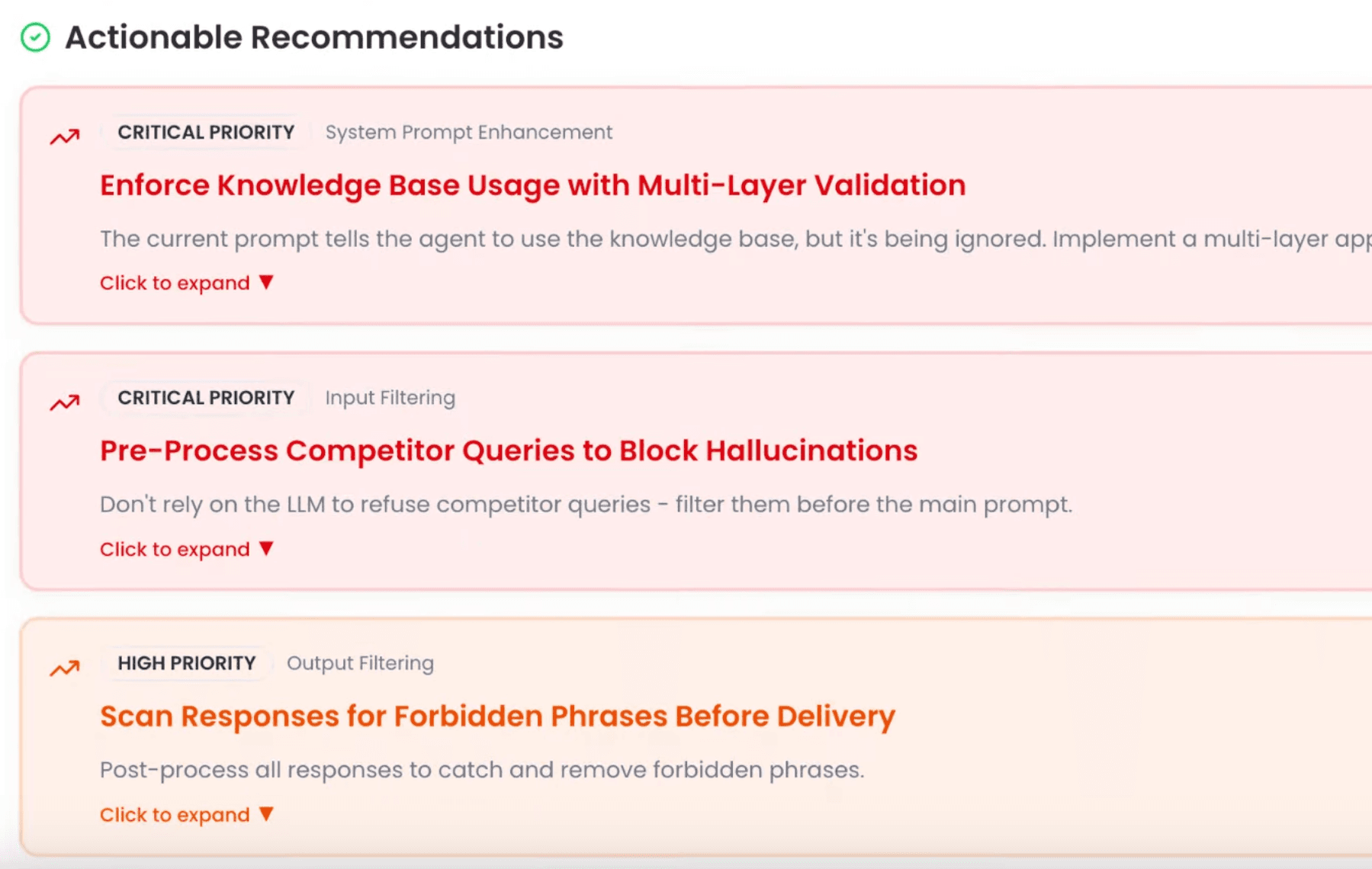
Evals that don't wait for your annotation team.
Noveum evals production traces with no expected answers or manual field-mapping. In a June 2026 benchmark of eight platforms, it alone parsed 440 raw traces into ready-to-score items and surfaced retrieval-skipped failures behind 78% of hallucinations. Langfuse requires human annotations and expected answers on every trace before meaningful evals can run.
Learn about evaluation framework
Evals that get fixed, not just flagged
Noveum surfaces not just what broke but exactly why, then hands you a NovaPilot recommendation report with actionable fixes for your prompts, tool calling, and pipelines. Other observability tools stop at flagging failures. You get a verified recommendation, not a list of failures to stare at.
See how NovaPilot worksWealthink
“We've used Noveumduring the early stages of our retrievalpipeline at Wealthink, and what stood out most was how proactively the team helped us evaluate output quality.
They ran a custom evalon our setup and surfaced inaccuracies in our retrievallayer that we were later able to independently validate.
That genuinely helped us diagnose issues faster.
The foundersthemselves regularly jump on calls with our team to debug problems and discuss what should be built next.
That level of involvement isn't easy at this stage, and you can feel it reflected in the product. The tracingcapabilities and overall UI have improved noticeably over the months we've been using it.
If you're integrating AI into your tech stack and care about catching failures before your users do, it's definitely worth checking out.”

Umang Joshi
Founder, Wealthink
Pricing posture
Observation-based pricing
More eval power, less spend
With Noveum you pay for evals and remediations, not raw observation volume. Smart trace sampling puts you in control of what gets scored, so your bill stays predictable as traffic grows. 106 calibrated scorers plus enterprise custom scorers give you more eval depth without building pipelines from scratch. NovaPilot recommendation reports close the loop on agent failures, and teams using Noveum typically reclaim around a third of their engineering bandwidth on eval and remediation work. For any company building agents in production, that is a straightforward return.
Common questions
Common questions
Is Noveum AI open source?
Noveum AI's core platform is proprietary. The noveum-trace SDK and the NovaEval evaluation framework are both open source and available on GitHub and PyPI. You can start evaluating traces with NovaEval without a paid account.
How long does integration take?
Most teams are capturing traces within 15 minutes. Noveum's Python SDK uses context managers or middleware. Add it to your agent, connect your API key, and your first traces start appearing in the dashboard immediately. In a June 2026 benchmark of eight LLM evaluation platforms, Noveum was also the only platform to ingest raw production traces with zero manual field-mapping, producing 440 ready-to-score items automatically from raw trace structure.
Can I self-host Noveum?
Noveum offers in-VPC enterprise deployment for teams with strict data residency requirements. This is available on the Enterprise plan. If full open-source self-hosting is a requirement, Langfuse is the stronger fit for that use case.
How is credit-based pricing different from observation-based?
Noveum charges by credit. One credit equals one eval or one NovaSynth test. Your bill is predictable regardless of how many raw traces you capture. Langfuse charges per observation unit, so costs grow every time your LLM traffic grows, even if you are not running more evaluations.
Can I migrate from Langfuse to Noveum?
Yes. Because Noveum's SDK is lightweight and framework-native, most teams run it alongside Langfuse during a trial period before fully switching. The evaluation output formats are different, but the trace instrumentation layer is straightforward to swap. In a June 2026 benchmark, Noveum was also the only platform to ingest raw production traces with zero manual field-mapping, which means the migration overhead on the evaluation side is lower than you might expect.
How does Noveum's scoring accuracy compare to other evaluation platforms?
In a June 2026 benchmark across eight LLM evaluation platforms (Noveum, Arize/Phoenix, Braintrust, Maxim, Galileo, Patronus, DeepEval, and Ragas), Noveum achieved the highest composite score of 0.999, compared to 0.650 for the next platform. On faithfulness specifically, Noveum caught 89% of hallucinations while wrongly flagging only 10% of correct answers, for an F1 of 0.84. Its scorers also ran at a median of 0.59 seconds per call, the fastest in the study and between 2 and 27 times faster than the other platforms. Langfuse was not one of the eight platforms benchmarked. The full methodology, dataset, and raw per-platform scores are published at noveum.ai.
Our take
For teams shipping AI agents to real users, Noveum is the stronger choice. You get 100+ built-in scorers, root cause analysis, trace sampling you control, enterprise custom scorers, and NovaPilot recommendation reports all from day one. In a June 2026 benchmark of eight LLM evaluation platforms, Noveum achieved the highest overall composite accuracy score of 0.999, catching 89% of hallucinations at a 10% false-alarm rate, with the fastest judge at 0.59 seconds per call, and the only platform to ingest raw traces without manual field-mapping. No setup loop. No maintaining pipelines. For growth-stage and enterprise companies, that is a no-brainer.
Langfuse is a solid open-source platform for developers who want to self-host and build their own eval stack. The MIT license and active community are real strengths. But if you need a complete production-grade eval and autofix loop without the engineering overhead, Noveum is built for that.
More comparisons
Next step
Put your production AI under control.
Start free and ship your first trace in 15 minutes — or book 30 minutes and we’ll integrate live on the call: your stack, your data, your first eval report before it ends.
SOC 2 Type II (in progress) · GDPR · On-prem & BYO ClickHouse available