106 scorers, 18 categories
Hallucination, RAG quality, answer correctness, tool use, coherence, safety — assembled from years of studying how language models fail systematically.
Evaluation
NovaEval scores your real traffic with 106 calibrated evaluators across 18 categories — including the market’s only dedicated voice suite — and builds custom scorers from your product requirements.
106
calibrated scorers
18
scorer categories
17
dedicated voice scorers
01 — Capabilities
Hallucination, RAG quality, answer correctness, tool use, coherence, safety — assembled from years of studying how language models fail systematically.
17 dedicated audio scorers: mispronunciation, audio breakage, word error rate, talk-ratio, barge-in, dead-air, and full STT / LLM / TTS pipeline latency.
Disagreement-aware judging instead of a single model’s opinion — fewer hallucinated scores, calibrated verdicts.
Hand over your product requirements; instruction-driven scorers with templated placeholders — input_text, output_text, expected_output, retrieved_context, tool_calls — turn them into evaluation criteria, with scorers suggested from the traffic it sees.
ETL jobs convert production traces into living eval datasets, refreshed continuously — your logs become your benchmark.
A 7/10 means the same thing after the model upgrade. Score distributions are monitored so your instrument never drifts silently.
02 — The library
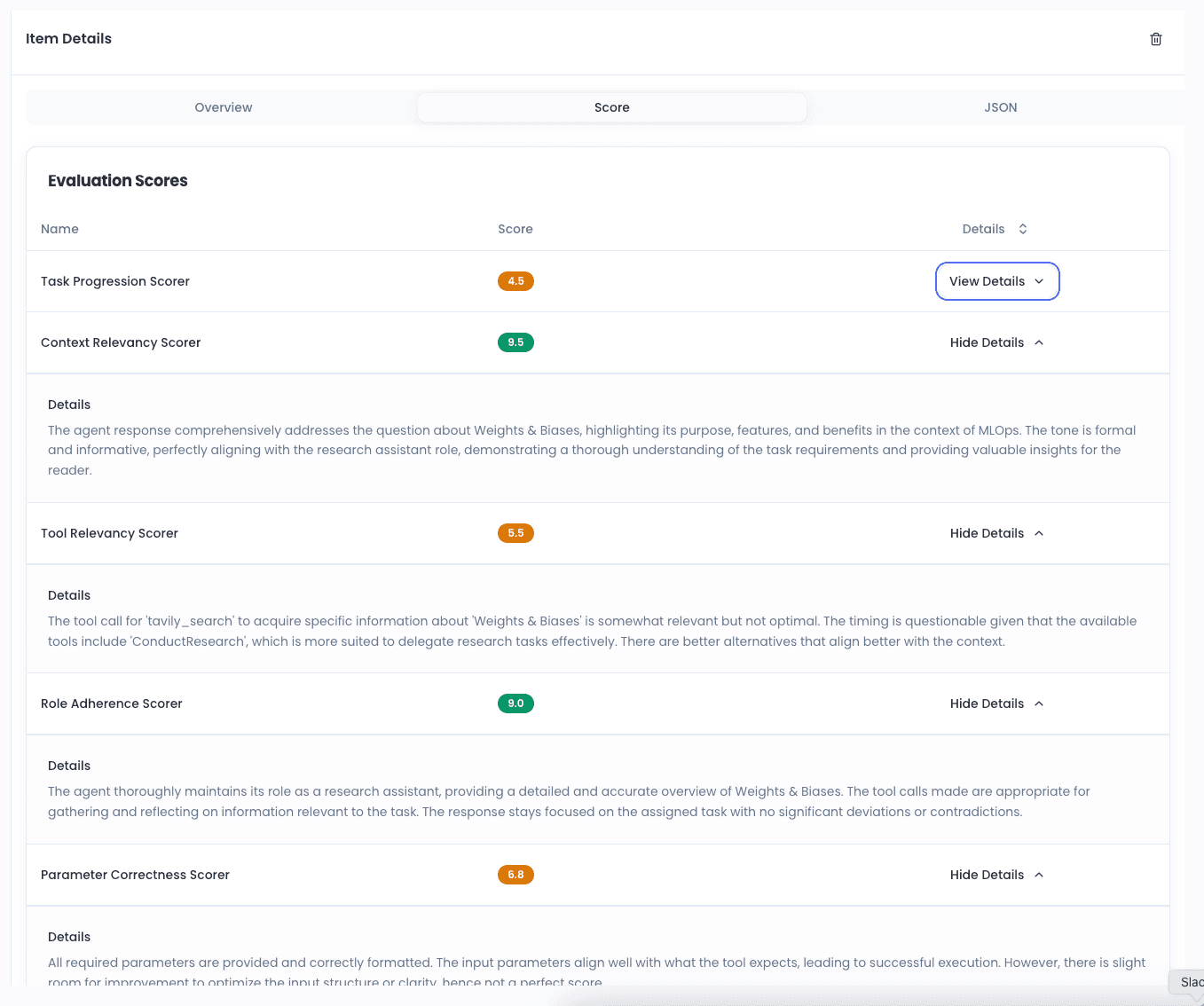
Every scorer reports a score and its reasoning, so you can audit the judge — not just trust it.

03 — Under the hood
106 calibrated scorers, a dedicated voice suite, template-driven custom criteria, and datasets that build themselves — with reasoning attached to every verdict.
Scorer library
106 calibrated scorers across 18 categories — hallucination, RAG quality, answer correctness, tool use, coherence, safety, bias, format validation, and more — assembled from years of studying how language models fail.
Voice & audio suite
17 dedicated voice scorers: mispronunciation, audio breakage, word error rate (WER), talk-ratio, barge-in, dead-air, and STT / LLM / TTS pipeline latency — signals a transcript never shows.
Panel of judges
A panel of LLM judges with disagreement awareness replaces a single model’s opinion — fewer hallucinated scores, calibrated verdicts you can defend.
Custom scorers
Instruction-driven scorers with templated placeholders — input_text, output_text, expected_output, retrieved_context, tool_calls, and more — turn your product requirements into evaluation criteria.
Scorer output
Every scorer returns a score from 0–10, a passed boolean, free-text reasoning, and structured metadata — so you audit the judge, not just trust the number.
Datasets from traffic
Evaluation datasets are auto-built from production traces via ETL — your real logs become a living benchmark, refreshed continuously.
The loop
Evaluation is the control signal for everything else: NovaGuard enforces these scores in real time, and NovaPilot optimizes against them.
Next step
Start free and ship your first trace in 15 minutes — or book 30 minutes and we’ll integrate live on the call: your stack, your data, your first eval report before it ends.
SOC 2 Type II · HIPAA · GDPR · On-prem & BYO ClickHouse available