Arize Phoenix vs Noveum AI: is observing your agents enough, or do you need them tested and fixed?
An honest comparison of tracing and visibility versus automated evaluation, voice quality scoring, synthetic testing, and auto-remediation, for AI teams deciding what they actually need.
Best for automated eval, voice quality scoring, pre-production synthetic testing, and teams that want actionable fixes.
Best for open-source, self-hosted observability and teams that need framework coverage with zero vendor lock-in.
“We recently switched from Arize Phoenix to Noveum AIfor our DarGlobal team, and the experience has been very positive. The Noveumteam helped us integrate directly into our existing codebase, which made onboarding much smoother. Compared to Arize, maintenance and deployment overhead dropped significantly, saving engineering effort and operational cost.
The biggest workflow improvement was AI-assisted debugging. We used to manually dig through logs, copy tracesinto Claude Code, and iterate from there. With Noveum, we analyze spans and tracesinside the platform and identify issues in place, which has saved a lot of debuggingtime. AI-based scorer recommendations also removed the guesswork of which scorers to build and configure. When we needed CrewAI, the team implemented it quickly and helped us integrate it properly. Shivam and the broader team have been responsive throughout, proactive on our feedback, and helpful in suggesting code changes when needed. Overall, the platform has streamlined our AI observability and debuggingwhile reducing operational overhead.”

Rehan Hussain Imam
Senior AI consultant, DarGlobal
Which tool is right for you?
Noveum tells you what to do next. Arize only shows you what happened.
Noveum is built for teams running agents in production who need more than a trace to look at. You connect your stack, and Noveum scores every output automatically using 100+ built-in scorers, runs NovaSynth synthetic sessions to catch issues before real users hit them, pinpoints root causes, and hands your engineers a structured fix report ready to use in their IDE. No manual review queues. No annotation sprints. No debugging sessions that stretch into days.
In a June 2026 benchmark of eight LLM evaluation platforms (Noveum, Arize/Phoenix, Braintrust, Maxim, Galileo, Patronus, DeepEval, and Ragas), Noveum achieved a composite accuracy score of 0.999 and Arize/Phoenix scored 0.576. On answer-relevance, Arize's scorer reached a correlation of 0.06 with the neutral reference, while Noveum's reached 0.78, meaning Arize's scorer could not reliably distinguish a good answer from a bad one on this dimension. Full methodology and raw scores are published at noveum.ai.
Where Noveum goes further
Evaluation, voice testing, auto-remediation: three things Arize leaves your team to figure out
You should not pay more just because your agents got busy
Noveum uses NovaEval with 100+ deterministic scorers, complemented by LLM-as-judge where deeper reasoning is needed. Deterministic scorers return the same result every time and cost less to run. In a June 2026 benchmark, Noveum's scorers ran at 0.59 seconds per call versus Arize's 1.04. Arize relies on LLM-as-judge prompts, so every scorer is an LLM call: at 10,000 traces a day, that adds up fast, with answer-relevance correlation of 0.06 versus Noveum's 0.78.
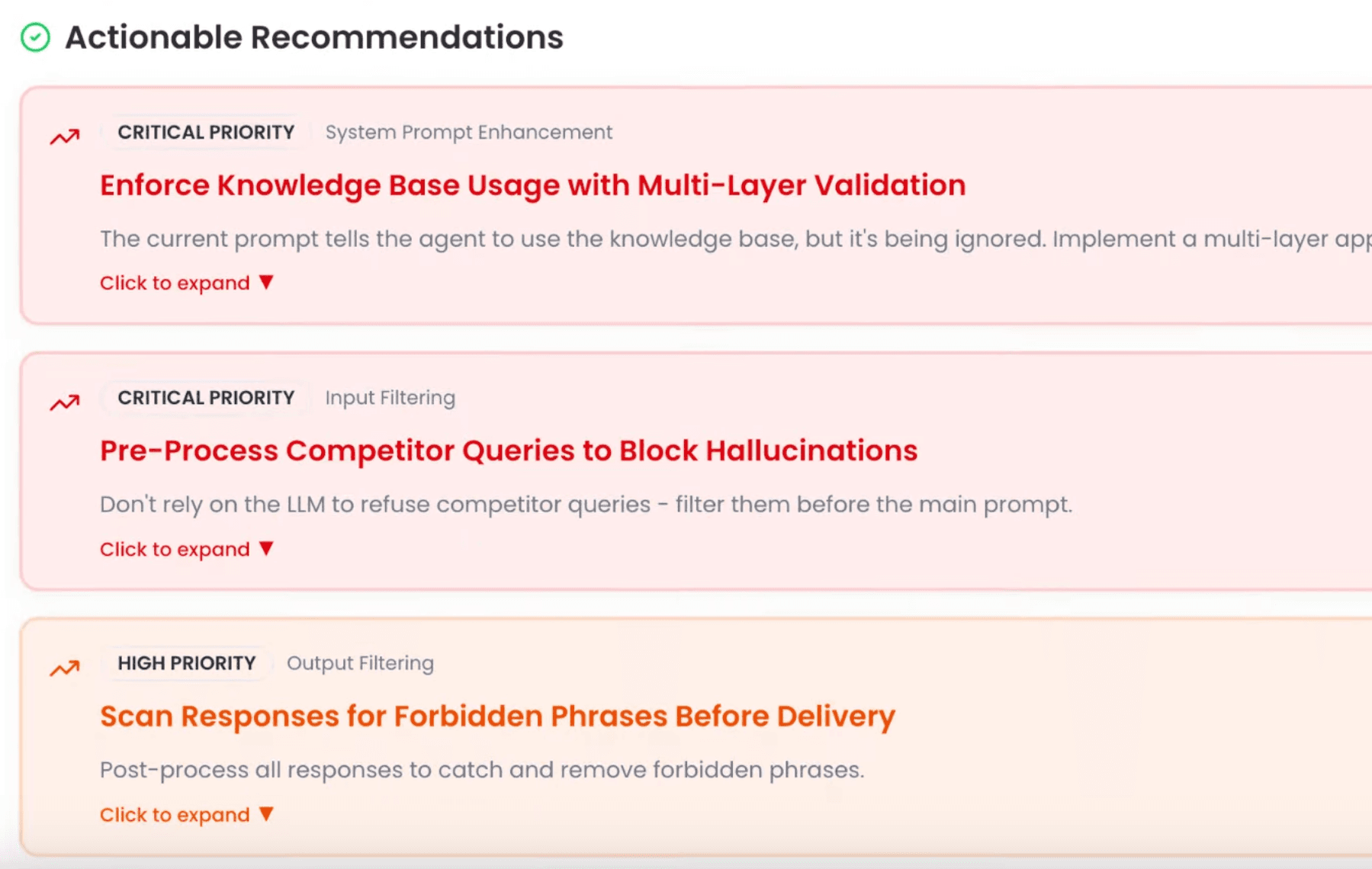
Test your voice agent before your users ever hear it
Noveum's voice scorers cover TTS quality, response latency, mispronunciation, interruption detection, and tone consistency. NovaSynth takes it further: define realistic personas, write test scenarios, and run those conversations through your live agent via voice or phone at scale. Every session is automatically scored so you find failures before your users do.

Your next bug comes with its own fix attached
When Noveum detects a failure pattern, it categorizes the root cause and produces a structured improvement document ready for your IDE. You go from something broke to here is what to change, without a debugging session in between.
Wealthink
“We've used Noveumduring the early stages of our retrievalpipeline at Wealthink, and what stood out most was how proactively the team helped us evaluate output quality.
They ran a custom evalon our setup and surfaced inaccuracies in our retrievallayer that we were later able to independently validate.
That genuinely helped us diagnose issues faster.
The foundersthemselves regularly jump on calls with our team to debug problems and discuss what should be built next.
That level of involvement isn't easy at this stage, and you can feel it reflected in the product. The tracingcapabilities and overall UI have improved noticeably over the months we've been using it.
If you're integrating AI into your tech stack and care about catching failures before your users do, it's definitely worth checking out.”

Umang Joshi
Founder, Wealthink
Pricing at a glance
Open source or fully managed cloud
The eval stack your team never has to build
Noveum charges by credit. You pay for evaluation and testing work, not team size or span volume. You get 100+ built-in scorers, voice pipeline scoring, NovaSynth synthetic testing, root cause analysis, and automated fix reports all included from the first paid plan. Arize AX Pro is $50 per month with unlimited users. As you move into AX Enterprise, pricing is custom and typically runs $50,000 or more per year at scale. For teams shipping voice agents and AI products at scale, Noveum's model stays predictable as you grow.
Common questions
Common questions
How quickly can I start getting evaluation scores with Noveum?
Most teams have scored traces running within 15 minutes. Install the SDK, wrap your LLM calls with the context manager, and 100+ scorers start running on every trace immediately. No eval infrastructure to configure, no expected answers needed, and no annotation work before you see real quality signal. In a June 2026 benchmark of eight LLM evaluation platforms, Noveum was also the only platform to ingest raw production traces with zero manual field-mapping, producing 440 ready-to-score items automatically without the operator mapping a single field.
What is NovaSynth and how does it work?
NovaSynth is Noveum's synthetic testing system for AI voice and chat agents. Instead of waiting for real users to expose quality issues, you define realistic personas with specific backgrounds, tones, and goals, write test scenarios covering happy paths, edge cases, and adversarial inputs, and NovaSynth runs those conversations through your live agent at scale via voice, text, or phone. Every session is automatically scored with voice quality, safety, and telephony scorers. You find the failures before launch. Arize does not have a synthetic testing equivalent.
Our agents handle domain-specific workflows. Can Noveum evaluate beyond generic metrics?
Yes. The Enterprise plan includes custom scorer development built around your product's specific evaluation logic. Domain-specific scorers sit alongside Noveum's 100+ built-in metrics and run in the same automated pipeline. A financial services team can score regulatory compliance. A healthcare team can score clinical accuracy. A voice AI team can score call-handling quality. You define what good looks like for your domain, and Noveum runs it at scale continuously without manual review cycles.
Is Arize Phoenix fully open source?
Arize Phoenix uses the Elastic License 2.0, not a permissive license like MIT or Apache 2.0. You can self-host and use it for free, but you cannot build a competing commercial service on top of the code. The managed cloud version, Arize AX, starts at $50 per month on the Pro plan with unlimited users.
How does Noveum pricing compare to Arize?
Noveum's tiers are public, from free to $99 per month, with Enterprise on custom pricing. You pay for evaluation and testing output, not team size or trace volume. Arize AX Pro is $50 per month flat with unlimited users. AX Enterprise is custom and typically runs $50,000 or more per year at scale.
How does Noveum's scoring accuracy compare to Arize Phoenix in independent benchmarks?
In a June 2026 benchmark across eight LLM evaluation platforms, Noveum achieved a composite accuracy score of 0.999 compared to Arize/Phoenix at 0.576. On faithfulness, both platforms are within the top statistical cluster, with Noveum at 89% recall / 10% false-alarm and Arize at 82% / 11%, so the confidence intervals overlap and neither can claim a clear faithfulness lead over the other. The more significant gap is on answer-relevance: Noveum's scorer correlated at 0.78 with the neutral reference while Arize's correlated at 0.06, meaning Arize's scorer could not reliably track whether an answer actually addressed the question on this dataset. On role-adherence across multi-turn conversations, Noveum scored 0.79 and Arize scored 0.59. Arize is the most balanced platform on tool-parameter scoring (100% recall, 81% specificity), which is worth noting if parameter correctness is your primary concern. Langfuse was not part of this benchmark.
Our take
Noveum is built for teams that need more than a trace to look at. You get 100+ scorers running on every output from day one, NovaSynth catching voice and agent failures before real users hit them, root cause analysis that tells you exactly why something broke, and automated fix reports your engineers can take straight into their IDE. In a June 2026 benchmark of eight LLM evaluation platforms, Noveum achieved the highest overall composite accuracy score of 0.999, with the fastest judge at 0.59 seconds per call and the only platform to ingest raw traces without manual field-mapping. Less time in logs. More time shipping better agents.
Arize Phoenix is a strong tracing tool. If your team self-hosts, needs zero vendor lock-in, and wants observability across many frameworks, it earns its place. In the same benchmark, Arize was within the top statistical cluster on faithfulness scoring and showed the most balanced tool-parameter scoring of any platform tested, worth noting if you need precise tool-call correctness alongside observability.
But observability alone does not close the loop. Knowing what happened is not the same as knowing what broke. And knowing what broke is not the same as knowing how to fix it. If you ship voice agents or need the full eval and remediation loop running automatically, Noveum is the platform that gets you there.
Next step
Put your agents in the loop
Production AI agents your customers can trust.
Trusted in production by enterprise and high-growth teams