9 Best AI Agent Evaluation Platforms in 2026: Features, Voice Eval Support, and Pricing Broken Down

Harkirat Singh

One of Noveum's customers ran an AI chat agent in production that told callers their product had 8 features.
The actual number was 5. The agent invented it 3 and no error was thrown. No alert fired. Every trace looked clean.
This is the most expensive class of failure in production AI today: confident, on-tone, yet factually wrong. It doesn’t crash. Instead, it quietly erodes trust, one conversation at a time.
When Noveum ran its autonomous optimization on that agent, hallucination detection scores moved from 2.8/10 to 9.5/10 in 10 minutes across 136 prompt variations.
This guide breaks down the 9 platforms built to catch failures like this, compared on Features, eval depth, voice eval support, pricing and how much of the actual remediation each one does for you.
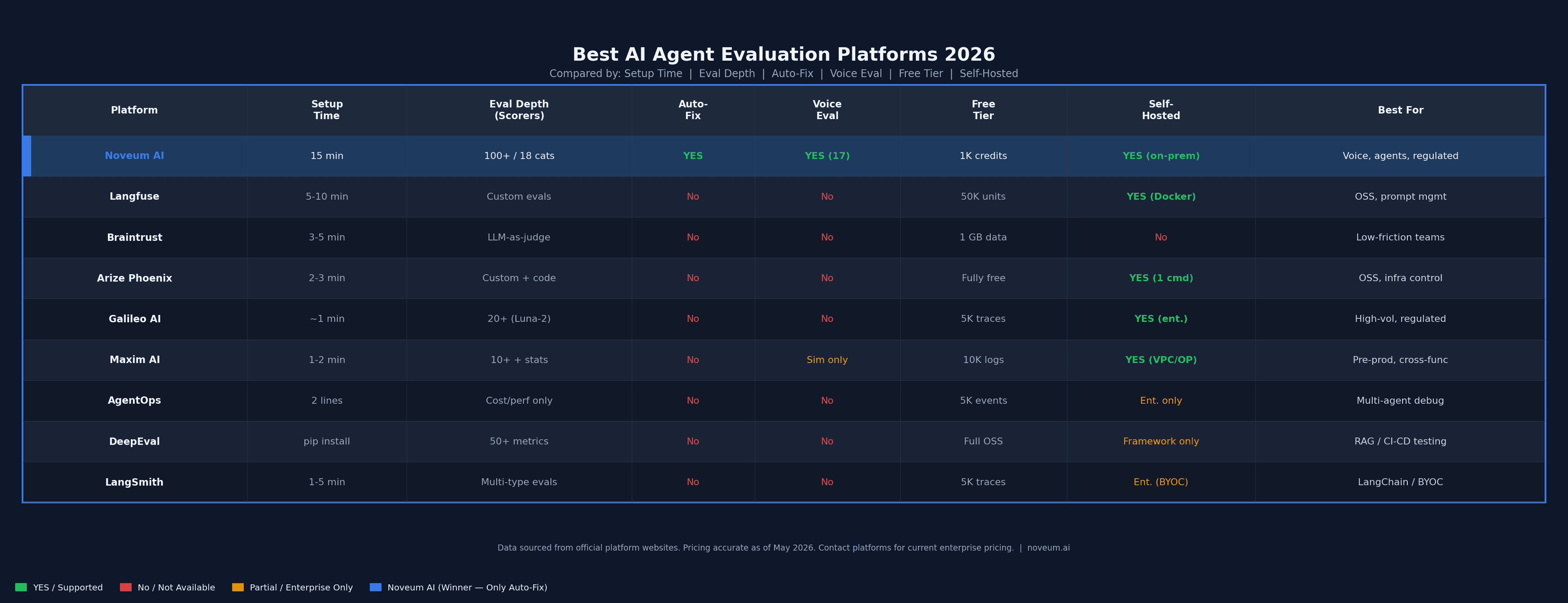
Before we get into the comparison, here’s a snapshot comparing 9 platforms:
What Is AI Agent Evaluation?
Think of a traditional software bug. It crashes, throws an error, and you fix it. AI agents don't work like that. When an AI agent fails, it doesn't crash. It keeps talking.
It answers confidently and wrong. It hallucinates a fact, picks the wrong API endpoint, or drifts off-persona in a way that's subtle enough to escape manual review but obvious enough to erode user trust over hundreds of conversations.
AI agent evaluation is the process of systematically measuring whether your agent is actually doing what it's supposed to do. Not just "did it respond?" but "did it respond accurately, faithfully, safely, and in the right voice?"
Good evaluation catches hallucinations before users do. It scores tool selection, measures retrieval quality in RAG pipelines, and for voice agents, checks whether the model even pronounced words correctly.
Here's a number worth sitting with: 80% of production AI issues get caught by users, not by monitoring systems. That's not a quality gap. That's a reputation risk. (Source: noveum.ai) Companies shipping AI agents without evaluation are flying blind at exactly the moment they can least afford to be.
The right evaluation platform answers three questions: How fast can you go from zero to live evals? How deeply can it measure what's actually going wrong? And can it do anything about the problem beyond just showing it to you?
9 Best AI Agent Evaluation Platforms in 2026
1. Noveum AI
Imagine having an eval engineering team working inside your production environment every hour of every day. Not just watching your agents. Not just alerting you when things go wrong. Actually finding the failure pattern, testing 136 different prompt fixes, and delivering the best one as a pull request to your codebase. That's Noveum.
Every other platform on this list tells you what's broken. Noveum fixes it.
The platform runs on four products that cover the entire loop. Noveum Trace captures 6 million traces per day with step-level granularity, logging every decision point, tool call, and LLM response in real time.
Nova Eval runs 100+ specialized scorers across 18 evaluation categories simultaneously. NovaSynth generates synthetic test scenarios before you have any real user traffic, so you catch edge cases before customers do.
NovaPilot, the auto-fix engine, tests 136+ prompt variations across four evolutionary generations and delivers verified improvements directly to your GitHub repo.
The voice evaluation story is in a category of its own. Noveum has 17 dedicated audio scorers measuring TTS quality, mispronunciation, speaking-over-user events, audio breakage detection, and voice pipeline latency.
For teams running voice agents on LiveKit, Twilio, or Pipecat, nothing else in this comparison comes close. For regulated industries, Noveum operates with true on-prem deployment. Your data never leaves your infrastructure.
For Agent Builders who sell white-label AI agents to their customers, the multi-tenant architecture means you can offer evaluation as a feature of your product, not just a tool your engineers use behind the scenes.
Setup takes 15 minutes. Four lines of code. Noveum's team sets up your evals on a live call. Competitors estimate weeks, sometimes months, for the same result.
Key Features:
- 102+ scorers across 18 evaluation categories, including custom scorers built from your actual PRD requirements
- NovaPilot auto-fix engine: tests 136+ prompt variations and delivers GitHub PRs with verified performance improvements
- 17 dedicated voice and audio scorers (TTS quality, mispronunciation, pipeline latency, speaking-over-user detection)
- NovaSynth synthetic test data generation for pre-production edge case testing
- True on-prem deployment for regulated industries where data cannot leave the organization
- White-label and multi-tenant architecture for Agent Builders selling agents to customers
- Native integrations with LangChain, LangGraph, CrewAI, LiveKit, Twilio, and Pipecat
Voice Eval Support: Full. 17 dedicated audio scorers covering TTS quality, mispronunciation, pipeline latency, speaking-over-user detection, and audio breakage. The only platform in this comparison with this level of voice-specific evaluation depth.
Pricing:
The free tier includes 1,000 credits per month, with support for up to 1M spans, 2 GB storage, 3 members, and 30 days retention. One credit equals one eval or one NovaSynth test.
Paid plans start with Pro at 99/month with 25K credits, 50M spans, 50 GB storage, 15 members, and 180 days retention.
Higher tiers like Max (599/month) provide significantly expanded capacity.
Ideal For: Teams building or operating production AI agents at 100K+ conversations per month. Voice AI teams running on LiveKit, Twilio, Pipecat, or custom-built voice pipelines.
Agent Builders offering white-label agents to customers. Enterprises in fintech, banking, healthcare, and telecom that need on-prem deployment and full audit trails. Any team that wants automatic performance improvement, not just monitoring.
Pros:
- Only platform with auto-fix: NovaPilot delivers GitHub PRs with verified improvements, not just alerts
- Broadest evaluation framework: 102+ scorers across 18 categories, no competitor matches this
- Only platform with 17 dedicated voice and audio evaluation scorers
- 15-minute setup with expert-guided eval configuration, not just tracing
- True on-prem for regulated industries with no data leaving your infrastructure
- Org-flat pricing means no per-seat cost as your team grows
Cons:
- Smaller open-source community compared to Langfuse or Arize Phoenix
- No open-source version for teams requiring code transparency
2. Langfuse
Langfuse is the most widely used open-source LLM observability platform, and it earns that position. Distributed tracing is where it shines. Every LLM request flows through a trace, broken into spans, each capturing tokens, latency, cost, and custom metadata. If your team needs to understand what went wrong at step 7 of a 12-step agent chain, Langfuse gives you that level of precision.
The prompt management capability is a standout. Versioning, caching, composability, annotation queues for human labeling, all inside the same platform where you trace your LLM calls. That's rare to find in one tool.
The Apache 2.0 open-source license means you can self-host entirely on your own infrastructure, using Docker or building from source. If vendor lock-in is a hard constraint, Langfuse is the natural starting point.
Features
- Distributed traces and spans with automatic token, latency, and cost capture
- LLM-as-judge evaluation plus custom Python eval functions
- Prompt versioning, caching, composability, and annotation queues built-in
- Self-hosted via Docker or managed cloud with no feature difference
- Native integrations with LangChain, LiteLLM, Vercel, and LlamaIndex
- Open-source Apache 2.0 with active GitHub community
Voice Eval Support: None. Langfuse is text-only. No audio or voice-specific scorers.
Pricing
- The Hobby plan is free with 50,000 units per month and no credit card required.
- The Pro plan starts at around 8 per 100,000 additional units.
- The Teams plan is $300 per month and adds annotation queues and extended data retention.
- Enterprise is custom pricing with 3-year retention, SSO (like Okta), custom rate limits, and dedicated support.
- (Source: langfuse.com/pricing)
Ideal For: Mid-sized engineering teams (5 to 50 engineers) building LLM-powered SaaS products who need open-source infrastructure, best-in-class prompt management, and the flexibility to self-host for compliance or cost reasons.
Pros
- Fully open-source (Apache 2.0) with real self-hosting capability
- Best prompt management in the comparison: versioning, caching, composability
- Generous free tier at 50,000 units per month with no credit card
- Strong multi-framework support across LangChain, LiteLLM, Vercel, LlamaIndex
Cons
- No auto-fix or auto-remediation of any kind
- No voice or audio evaluation
- No synthetic test data generation
- Limited agent-specific metrics; stronger for general LLM apps
3. Braintrust
Braintrust takes a focused approach. Capture production traces, turn them into evaluation datasets, iterate. The friction is minimal by design. One gigabyte of free data, unlimited users, unlimited projects, unlimited experiments on the free tier.
The integrated web playground is its sharpest edge. Product managers and non-engineers can adjust prompts, run experiments against production data, and see results without writing code. It's the most accessible experimentation environment in this comparison.
The tradeoff is depth. Braintrust captures request-response pairs, not distributed spans. If you need to understand what happened at step 9 of a 15-step agent chain, you won't find that answer here.
Features
- Production trace capture with automatic cost, latency, and token metadata
- LLM-as-judge and custom evaluation metrics
- Web-based playground for no-code prompt experimentation and model comparison
- Dataset creation directly from production traces
- Unlimited users, projects, datasets, and experiments at all pricing tiers
Pricing
- The free plan gives you 1 GB of processed trace data per month, with overages at 2.50 per 1,000 evals.
- The Pro plan is approximately 3 per GB and $1.50 per 1,000 evals.
- Enterprise pricing is custom.
- All plans include unlimited users.
- (Source: braintrust.dev/pricing)
Ideal For: Product-focused AI teams who want the lowest possible onboarding barrier and a web-based playground for rapid prompt iteration. Best for teams transitioning from staging to production who need immediate quality visibility without infrastructure overhead.
Voice Eval Support: None. Text and request-response only.
Pros
- Lowest onboarding friction: free tier, no credit card, unlimited users and projects
- Integrated no-code playground accessible to product managers and non-engineers
- Clean, predictable pricing metric based on data volume
Cons
- Cloud-only: no self-hosted or on-prem option, which blocks regulated industries
- No auto-fix capability
- Shallow tracing model: request-response only, not distributed span-level tracing
- No voice or audio evaluation
4. Arize Phoenix
Arize Phoenix is the choice when infrastructure control is non-negotiable. It's fully open-source, fully free, with zero feature gates anywhere. Every capability in the managed cloud version exists in the self-hosted version. No paywalls, no upgrade nudges.
Phoenix is built on OpenTelemetry (OTEL), the industry standard for distributed observability. That means your instrumentation isn't locked to Arize. If you ever migrate platforms, your traces go with you. In a market full of vendor lock-in, that portability is meaningful.
Self-hosting is also unusually simple. A single Docker container. PostgreSQL for production. No ClickHouse, no Redis, no S3 required. One command spins it up locally for development. (Source: arize.com/docs/phoenix/self-hosting)
Features
- Fully open-source with zero feature gates (Apache 2.0 license)
- OpenTelemetry-based tracing that is portable and framework-agnostic
- Auto-instrumentation for LlamaIndex, LangChain, DSPy, Mastra, and Vercel AI SDK
- LLM-as-judge, code-based, and human-in-the-loop evaluation types
- Prompt versioning with semantic tagging ("production", "experimental") and A/B testing
- Easiest self-hosting experience: single Docker container plus PostgreSQL
Voice Eval Support: None. Text and LLM trace focused only.
Pricing
- The open-source Phoenix (self-hosted) version is completely free, with usage (spans, storage, retention) fully user-managed and no enforced limits.
- A managed cloud version is available via Arize AX Free, which includes up to 25K trace spans/month, 1 GB ingestion, and 15 days retention, along with features like online evals, product observability, and community support.
- Paid plans start with AX Pro at $50/month, offering 50K spans/month, 10 GB ingestion, 30 days retention, higher rate limits, and email support.
- For larger teams, AX Enterprise provides custom pricing with configurable usage limits, extended retention, dedicated support, SLAs, compliance (SOC2, HIPAA), and options for self-hosting, data residency, and multi-region deployments.
- Overall, Arize follows a usage-based + tiered SaaS model, while keeping the core Phoenix offering open-source and flexible for self-hosted setups.
Ideal For: Engineering teams that prioritize infrastructure control, open standards, and zero vendor lock-in. Especially strong for LlamaIndex and LangChain teams who want full auto-instrumentation without manual trace configuration.
Pros
- 100% open-source, every feature available without paywalls
- Simplest self-hosting: single Docker container versus multi-service stacks
- OpenTelemetry standard means your instrumentation is portable, not proprietary
- Python, TypeScript, and Java SDKs all supported
Cons
- No auto-fix or automated remediation
- No voice or audio evaluation
- Fewer pre-built evaluators than competitors; more custom logic required
- Engineering-centric: no no-code UI for product or business teams
5. Galileo AI
Speed and cost efficiency. That's Galileo's core proposition, and the numbers behind it are hard to ignore.
Its proprietary Luna-2 models, fine-tuned from Llama at 3 billion and 8 billion parameter sizes, evaluate agent outputs at an average latency of 152ms and at 97% lower cost than running GPT-3.5 for evaluation. For a team running a million evaluation calls per month, GPT-3.5 evaluation costs approximately 20 per month for the same volume. (Source: venturebeat.com, galileo.ai/blog)
Luna-2's accuracy is also not a compromise. It achieves an AUROC of 0.78 on agent evaluation benchmarks, outperforming GPT-3.5, TruLens Groundedness, and RAGAS Faithfulness. (Source: arxiv.org/pdf/2602.18583) This is the rare case where the cheaper option is also the more accurate one.
Features
- Luna-2 evaluation models: 152ms latency, 97% lower cost than GPT-3.5 evaluation
- 20+ pre-built evaluators: RAG quality, tool selection accuracy, task completion, PII detection, toxicity scoring
- Insights Engine: automatic failure mode identification with root cause recommendations
- Real-time production guardrails via Luna-2 that can block or flag bad outputs inline
- On-prem and VPC deployment: HIPAA, GDPR, and SOC2 Type II compliant
Voice Eval Support: None. Galileo's evaluators cover text-based agent outputs and RAG pipelines only.
Pricing
- The free tier covers 5,000 traces per month with full access to the Agent Reliability Platform.
- The Professional plan is $100 per month for 50,000 traces.
- Business and Enterprise tiers are custom with on-prem deployment and dedicated support available.
- (Source: prnewswire.com, checkthat.ai/brands/galileo-ai)
Ideal For: High-volume production systems where real-time evaluation at low latency and low cost is the primary constraint. Regulated industries such as healthcare and finance that need both strong evaluation accuracy and on-prem data sovereignty.
Pros
- 97% cheaper evaluation than GPT-3.5 via Luna-2 (verified third-party cost comparison)
- Sub-200ms eval latency makes real-time production guardrails economically viable
- Purpose-built agent metrics designed ground-up for multi-step workflows, not adapted from LLM evaluation
- On-prem and VPC deployment for HIPAA and GDPR compliance
Cons
- No auto-fix capability
- No voice or audio evaluation
- Limited prompt management features outside the evaluation context
- No pre-production simulation engine
6. Maxim AI
Maxim solves a problem most platforms ignore: the gap between "it works in testing" and "it works in production at scale."
Its simulation engine generates synthetic user interactions across different personas and edge cases before you have any real traffic. You can run your agent through thousands of scenarios before a single real user sees it. Maxim claims teams catch 80% of failures before production using this approach. (Source: getmaxim.ai) Whether or not that number holds universally, the principle is sound: waiting for users to surface failures is the most expensive QA strategy.
The cross-functional angle is equally thoughtful. Maxim's no-code UI means product managers can define evaluation criteria, run tests, and analyze results without engineering involvement. The CI/CD integration is the deepest in this comparison, with native GitHub Actions, Jenkins, and CircleCI support that blocks deployments when evaluation scores drop.
Features
- Pre-production simulation engine: synthetic user interactions at scale across personas and edge cases
- No-code evaluation UI that enables product managers and business analysts to run tests independently
- CI/CD integration with GitHub Actions, Jenkins, and CircleCI including automated quality gates
- Flexible deployment: SaaS, in-VPC zero-touch, on-prem, air-gapped, multi-cloud
- SDKs available in Python, TypeScript, Java, and Go
- Voice simulation for testing voice agent behavior before production
Voice Eval Support: Partial. Maxim offers voice simulation, meaning it can simulate voice-style interactions in pre-production testing. It does not score audio quality, TTS output, mispronunciation, or pipeline latency the way a full voice evaluation platform would.
Pricing
- The Developer plan is free with 10,000 logs per month, 3-day retention, and up to 3 seats.
- The Professional plan is $29 per seat per month for 100,000 logs with 7-day retention and simulation run access.
- The Business plan is $49 per seat per month for 500,000 logs with 30-day retention and role-based access control.
- Enterprise pricing is custom with on-prem, compliance certifications, and 24/7 support.
Ideal For: Cross-functional AI teams where product managers and business analysts need to participate in quality validation. Teams building agents into CI/CD pipelines who want automated evaluation gates before every deployment.
Pros
- Pre-production simulation catches failures before real users do
- No-code UI enables non-engineers to run evaluations independently
- Deepest CI/CD integration in the comparison: GitHub Actions, Jenkins, CircleCI
- Broadest SDK language support: Python, TypeScript, Java, Go
Cons
- No auto-fix capability; simulation surfaces failures but engineers still remediate manually
- Seat-based pricing can scale expensively for larger teams
- Production monitoring is less mature than observability-first platforms
- Not fully open-source
7. AgentOps
AgentOps fills a specific role exceptionally well. If you're building multi-agent systems with CrewAI, Autogen, OpenAI Agents SDK, or similar frameworks, it offers the widest compatibility layer in this comparison. Four hundred LLMs and agent frameworks supported out of the box. Two lines of code to initialize.
The time-travel debugging is the feature that makes teams stay. When an agent makes an unexpected decision mid-session, you don't just see the final output. You rewind the session to the exact moment it happened and step through the execution event by event. That kind of root-cause precision recovers hours of debugging time that would otherwise be spent re-running agents and guessing.
Features
- Session replay with time-travel debugging: rewind to any point in an agent execution with event-level precision
- Event waterfall visualization showing nested agent calls, LLM invocations, and tool usage in sequence
- 400+ LLM and framework integrations (CrewAI, Autogen, OpenAI Agents SDK, LangChain, AG2)
- Real-time cost tracking across all connected LLMs with fine-tuning optimization support
- Prompt injection attack detection built into the monitoring layer
- SOC-2, HIPAA, and NIST AI RMF compliance on Enterprise plans
Voice Eval Support: None. AgentOps monitors agent execution flow and costs. No audio or voice-specific evaluation.
Pricing
- The platform follows a usage-based pricing model starting with a base seat cost of $40 per user per month. In addition to seats, pricing scales based on usage, with span uploads and LLM tokens billed separately.
- The first 100K span uploads per month are free, after which usage is charged at $0.10 per 1K spans.
- LLM token usage is priced at approximately $0.20 per 1M tokens, allowing costs to scale with actual workload.
- This means the total monthly cost is a combination of seat-based pricing and usage-based charges, rather than fixed tiers.
- Enterprise pricing remains custom and typically includes advanced capabilities such as dedicated support, custom infrastructure on AWS, GCP, or Azure, security features, and flexible data retention policies.
Ideal For: Teams building multi-agent systems with CrewAI, Autogen, or OpenAI Agents SDK who need session replay, cost optimization, and time-travel debugging to understand unexpected agent behavior.
Pros
- Widest framework support: 400+ LLMs and agent frameworks, more than any other platform here
- Time-travel debugging is the most detailed root-cause tool in the comparison
- Two-line setup with automatic instrumentation, no code refactoring needed
- Enterprise compliance: SOC-2, HIPAA, NIST AI RMF
Cons
- No auto-fix capability
- No voice or audio evaluation
- Quality evaluation metrics are limited: cost and performance focused, not output quality scoring
- TypeScript SDK is still in Alpha
8. DeepEval
DeepEval calls itself "Pytest for LLMs," which is exactly what it is. It's an open-source Python testing framework where you write LLM test cases like unit tests, run them with a single CLI command, and get pass-fail results with detailed reasoning. If your team lives in pytest and CI/CD pipelines, DeepEval slots into that workflow without friction.
The metric library is the broadest in this comparison at 50+ research-backed evaluators, covering hallucination detection, faithfulness, RAGAS metrics for RAG pipelines, bias and toxicity scoring, conversation completeness, and custom LLM-as-judge setups. The framework is 100% free and runs entirely offline. No platform dependency for the core evaluation loop.
The optional Confident AI cloud platform adds team collaboration, production tracing, and Git-based prompt management with eval-gated merge permissions.
Features
- 50+ research-backed metrics: hallucination, faithfulness, RAGAS, bias, toxicity, task completion, and more
- Pytest-compatible CLI for running evaluations in CI/CD pipelines with pass-fail gates
- Git-based prompt management on Confident AI with eval-gated merge permissions
- Completely open-source framework (Apache 2.0) with 100% offline operation, no platform dependency
- Trace storage on Confident AI at $1 per GB per month, approximately 3x cheaper than alternatives
Voice Eval Support: None. Python-only, text-based evaluation framework.
Pricing
- The DeepEval framework is 100% free and open-source with no feature restrictions.
- The Confident AI platform's free tier includes 5 test runs per week and 1 GB of storage per month.
- The Starter plan is $19.99 per user per month with 20,000 traces and unlimited test runs.
- Premium is custom pricing.
- Trace storage overages on paid plans are $1 per GB per month, significantly cheaper than alternatives.
Ideal For: Python engineering teams building RAG applications, chatbots, or LLM services who want systematic quality gates and regression testing integrated into CI/CD pipelines. Best for pytest-familiar developers who want evaluation to feel like unit testing.
Pros
- 100% open-source framework with zero vendor lock-in and zero cost
- 50+ research-backed evaluation metrics: the broadest metric library in this comparison
- Best CI/CD integration for regression testing: builds fail when quality drops below threshold
- Framework-agnostic: works with any LLM and any inference setup
Cons
- No auto-fix capability
- No production observability or real-time monitoring of live agents
- Python-only: no TypeScript or JavaScript SDK for non-Python teams
- Heavy reliance on LLM-as-judge means high API costs at scale for large evaluation runs
9. LangSmith
LangSmith is the platform most LLM engineering teams reach for first, and it earns that trust. The observability is comprehensive. The annotation queues for collecting human expert feedback are the best in this comparison. And unlike what its name implies, it works with OpenAI SDK, Anthropic, Vercel AI, LlamaIndex, and custom implementations, not just LangChain.
Framework-agnostic tracing with a one-to-five line setup. Production trace capture with configurable 14-day or 400-day retention. Multiple evaluator types in one place: human annotation queues, LLM-as-judge, heuristic code checks, pairwise model comparisons, and custom Python or TypeScript evaluators.
For data residency, the Bring-Your-Own-Cloud option deploys LangSmith on your AWS, GCP, or Azure infrastructure. That's the right answer for healthcare, finance, or any industry where data cannot flow through a third-party SaaS.
Features
- Framework-agnostic tracing: works with OpenAI, Anthropic, Vercel AI, LlamaIndex, LangChain, and custom implementations
- Multiple evaluator types: human annotation queues, LLM-as-judge, heuristic checks, pairwise model comparisons, custom Python or TypeScript evaluators
- Configurable trace retention: 14 days standard or 400 days extended
- Bring-Your-Own-Cloud (BYOC) deployment on the customer's AWS, GCP, or Azure
- Python and TypeScript SDKs both fully production-grade
Voice Eval Support: None. LangSmith evaluates LLM application traces only.
Pricing
- The Developer plan is free with 5,000 traces per month and 14-day retention.
- The Plus plan is 2.50 per additional 1,000 traces.
- Extended 400-day retention adds $5 per 1,000 traces.
- Enterprise pricing is custom and includes BYOC, self-hosted Kubernetes deployment, SSO, and Okta integration.
- (Source: langchain.com/pricing, pecollective.com/blog/langsmith-pricing)
Ideal For: Teams using LangChain or LangGraph, or any LLM engineering team that needs human annotation queues for expert feedback and BYOC deployment for data residency compliance.
Pros
- Best human annotation queues: distributed expert feedback with assignment, collection, and calibration
- Fully framework-agnostic despite the LangChain branding
- Python and TypeScript SDKs both production-ready and well-documented
- BYOC and self-hosted deployment for data residency and compliance requirements
Cons
- No auto-fix capability
- Volume-based pricing scales steeply for high-throughput production systems
- No open-source self-hosting without an Enterprise contract
- No voice or audio evaluation
Pricing Overview
Here's where each platform starts and what the free tier gets you:
- Noveum AI: Free tier with 1,000 credits per month (monitoring and tracing included); paid tiers on request; org-flat pricing with no per-seat costs
- Langfuse: Free at 50,000 units per month; Pro from approximately $29 per month; self-hosted always free
- Braintrust: Free at 1 GB of trace data per month; Pro from approximately $249 per month
- Arize Phoenix: Completely free and open-source with all features; no paid tiers for core OSS version
- Galileo AI: Free at 5,000 traces per month; Professional at $100 per month
- Maxim AI: Free at 10,000 logs per month; Professional from $29 per seat per month
- AgentOps: Free at 5,000 events per month; Pro at $40 per month with unlimited events
- DeepEval: Framework is 100% free open-source; Confident AI platform from $19.99 per user per month
- LangSmith: Free at 5,000 traces per month; Plus from $39 per seat per month
Which Platform Wins Each Dimension?
Setup Time
Noveum AI. Most platforms can wire up tracing in a few lines of code. What takes weeks at competitors is the evaluation setup: defining scorers, calibrating thresholds, connecting evals to production traces. Noveum configures all of that in 15 minutes on a live call. You leave with live evals running, not just live tracing.
Eval Depth
Noveum AI, with 100+ scorers across 18 categories. Second place goes to DeepEval with 50+ research-backed metrics, followed by Galileo AI with 20+ Luna-2-powered evaluators. The critical distinction with Noveum is that scorers are built from your actual product requirements, not from generic templates that may or may not apply to your use case.
Auto-Fix
Noveum AI, and only Noveum AI. This category has one entry. NovaPilot is the only engine in the market that generates, tests, and ships fixes automatically. Every other platform in this comparison detects failures and stops. Noveum detects failures and then tests 136 prompt variations across four evolutionary generations to find what actually works, then puts it in a pull request.
The Bottom Line
If you are building production AI agents, the platforms you choose to evaluate them directly affects how often they fail in front of your users. Most platforms in 2026 give you visibility. Some give you metrics. A very small number give you answers about what to do next.
Noveum AI is the only platform that closes the full loop: monitor, evaluate, and fix. For teams running voice agents, for Agent Builders who stake their product reputation on agent reliability, and for enterprises in regulated industries that need on-prem deployment and audit trails, Noveum is purpose-built for exactly that. With 95%+ agent success rates achieved from typical starting points of 20 to 30%, and a 15-minute setup that actually delivers live evals rather than just live tracing, it makes the strongest case for the most demanding production environments.
Start with Noveum's free tier at noveum.ai and see what your agents are actually doing in production.
Frequently Asked Questions
Q1. What is the best AI agent evaluation platform in 2026?
The best platform depends on your primary constraint. If you need automatic performance improvement and not just monitoring, Noveum AI is the only platform with auto-fix capability. If open-source and self-hosting are non-negotiable, Langfuse or Arize Phoenix are strong choices. If cost-efficient large-scale evaluation is the priority, Galileo AI's Luna-2 models offer 97% cost reduction compared to GPT-3.5 evaluation.
Q2. How is AI agent evaluation different from standard LLM evaluation?
Standard LLM evaluation measures single-turn input-output quality: did the model respond correctly to this prompt? AI agent evaluation is significantly more complex. Agents take multiple steps, use tools, make decisions, and often fail not at the individual LLM call level but at the coordination level: did the agent select the right tool, pass the correct parameters, recover gracefully from a failure, and complete the multi-step task successfully? Platforms built for agents track these decision chains, not just individual LLM responses.
Q3. Do I need an AI agent evaluation platform if I'm still in early development?
Yes, and earlier is better. The most expensive time to discover evaluation gaps is in production, where failures are user-facing. Platforms like DeepEval and Arize Phoenix let you run evaluations in development with zero infrastructure cost. Noveum's NovaSynth generates synthetic test data so you can evaluate your agent against edge cases before any real user encounters them. Starting evaluation in development means you ship to production with known quality baselines, not unknown failure modes.
Get Early Access to Noveum.ai Platform
Join the select group of AI teams optimizing their models with our data-driven platform. We're onboarding users in limited batches to ensure a premium experience.