AI Agent Debugging: From Failed Eval to Reviewed Fix With an Auto-Analysis Layer
Pragati Tripathi
The eval flagged a failure. You opened the trace. You found the bad span — the one where the agent hallucinated a policy answer even though the retrieved context was correct. The scorer caught it. The dashboard logged it.
Now what? This is the AI agent debugging problem nobody talks about.
Someone still has to inspect the prompt, form a hypothesis about the root cause, write a patch, test it against a handful of scenarios, check whether it breaks something else, adjust, retest, write it up, and open a PR. That entire sequence happens manually. The eval did its job. The auto-analysis didn't exist. So the failure sat in a queue until the right engineer had time to dig in.
This is where most AI agent debugging workflows stall — and where most observability platforms quietly stop.
What You'll Get From This AI Agent Debugging Post:
- Why eval dashboards are necessary but incomplete for production AI teams
- What the real post-eval debugging workflow looks like, and where it breaks down
- What "auto-analysis" and "auto-fix" should actually mean for ML teams
- Where NovaPilot fits in the evaluation loop and what it can and cannot do
- What a production-ready analysis workflow should include before a team trusts a recommended fix
- A comparison of observability, evaluation, and auto-analysis by layer, and how AI agent eval analysis fits in
AI Agent Debugging in 2026: From Failed Eval to Reviewed Fix
Here is the real sequence for most ML teams after a production eval flags a failure:
- Eval scores a faithfulness failure on a policy-related query.
- The engineer opens the trace and finds the relevant span.
- Retrieved context looks correct. The prompt is overriding it.
- Engineer hypothesizes a prompt fix — adds an instruction to prioritize retrieved context.
- Runs a few local tests. Looks good.
- Pushes the change. A different edge case breaks — now the agent is too literal and refuses to interpolate anything not directly in the retrieved text.
- Adds another instruction to handle the edge case.
- Reruns the test suite. Passes.
- Opens a PR.
- Waiting for review.
The whole sequence takes anywhere from half a day to three days depending on how well-understood the failure pattern is, whether the test suite is comprehensive, and — critically — whether the engineer who wrote the original prompt is the one debugging the AI agent.
That last point matters more than most teams admit. Prompt debugging is context-dependent. If the person on call did not write the prompt, their first hour is just catching up. If the failure is in an AI multi-agent handoff, they may need to understand the architecture of two or three agents before they can even locate the root cause.
The result: slow fixes, inconsistent coverage, and the same failure class appearing again six weeks later because the root cause was patched but not fully understood.
AI Agent Auto-Fix Is Not "Let the Model Rewrite Production"
Before going further: if you are skeptical of anything called "auto-fix" without human approval in a production AI context, that skepticism is correct.
Letting an LLM rewrite production system prompts and ship them unsupervised is not a credible workflow. Any tool that positions auto-fix as autonomous deployment is either overselling or describing something genuinely unsafe for regulated or high-stakes production systems.
What a credible AI agent eval analysis and recommendation workflow actually looks like:
- Detect the failure pattern — not just a single failed item, but a recurring class of failures with a common root cause signal
- Identify the likely root cause — which part of the system (prompt, routing logic, tool parameters, retrieval configuration) is the probable source
- Generate candidate fixes — specific, copyable recommendations tied to the identified root cause
- Test candidates against relevant scenarios — including edge cases related to the failure class
- Compare against baseline behavior — check whether the candidate fix degrades performance on cases that were previously passing
- Produce a reviewable recommendation — clear, specific, human-readable, with the evidence that produced it
- Keep engineers in control of testing, approval, and deployment — the analysis compresses the debugging loop; it does not remove the human from it
The key distinction: auto-analysis accelerates the journey from flagged failure to actionable recommendation. The engineer still owns the judgment call, the test, and the deployment.
The Solution: Add an Auto-Analysis Layer After Evaluation
The fix is not replacing traces, scorers, or dashboards. It is adding the layer they miss: auto-analysis that turns eval failures into grouped patterns, likely root causes, and reviewable recommendations.
Noveum’s NovaPilot is the layer after evaluation. It does not replace tracing or scoring — it reads from them.
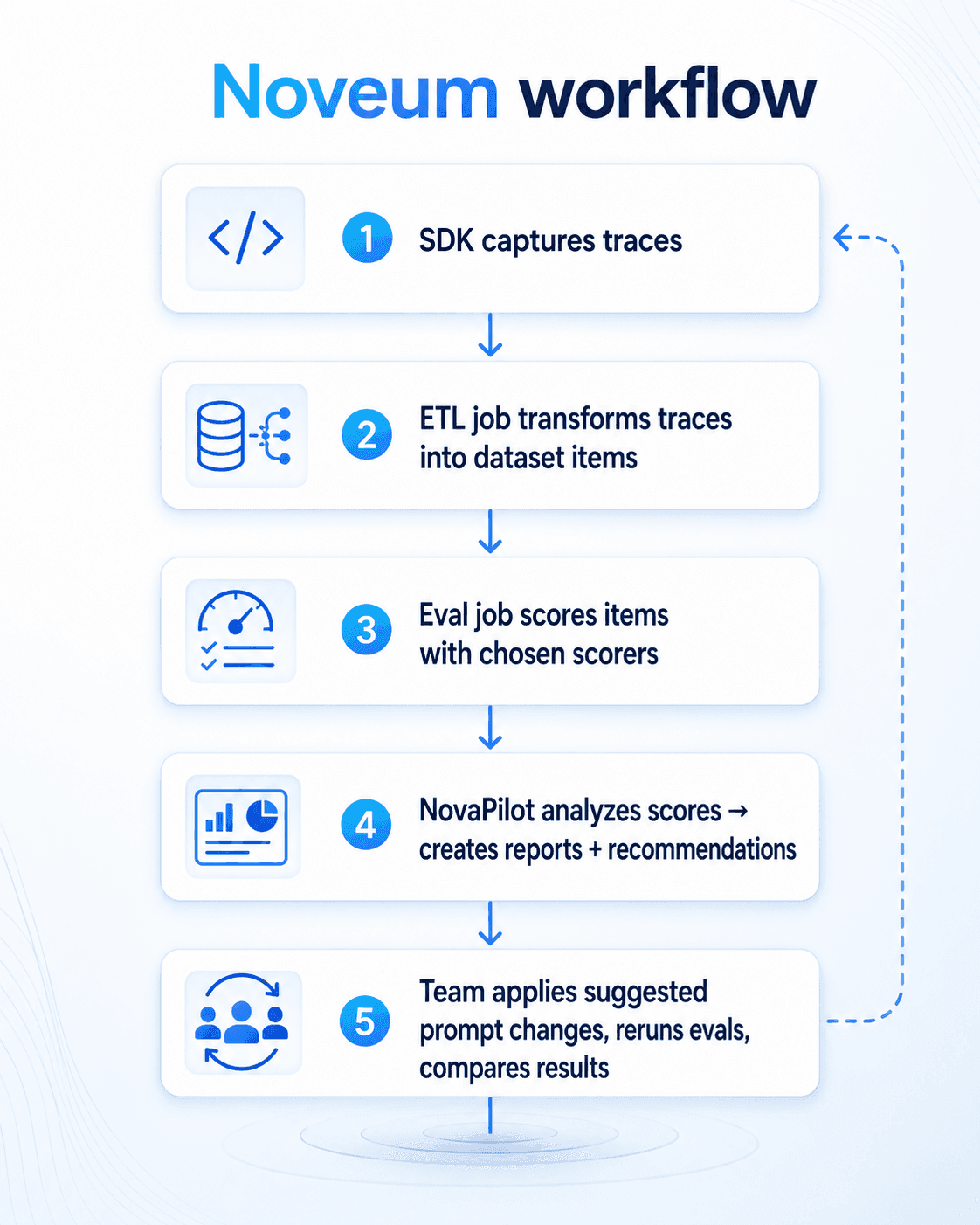
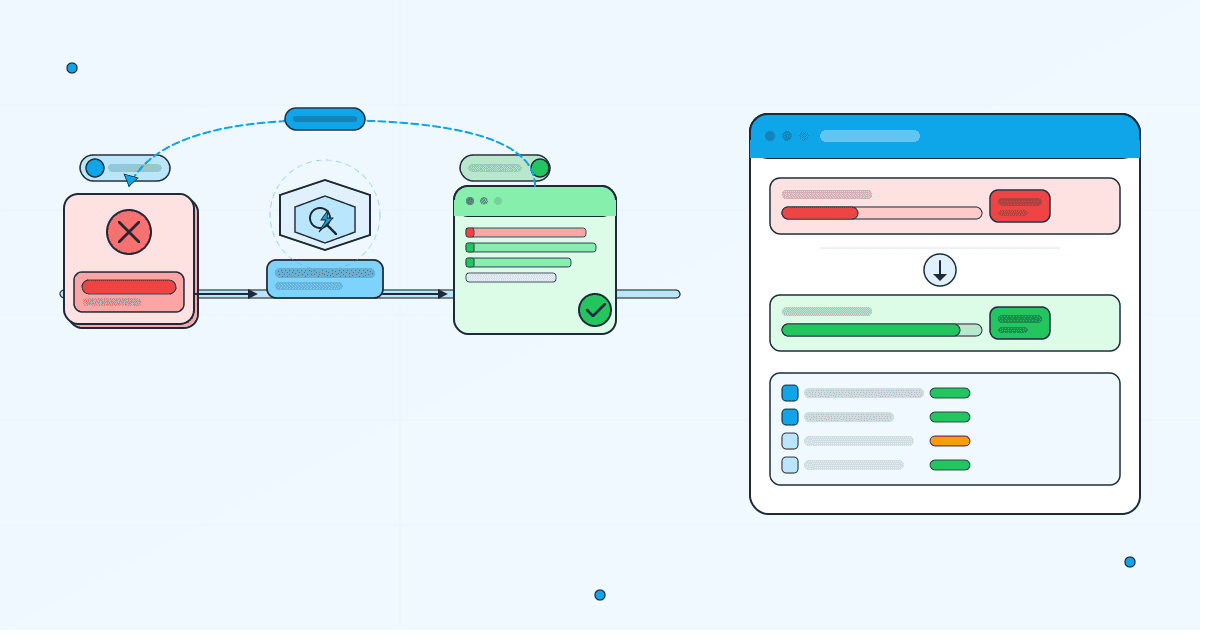
Noveum Trace captures what happened. Nova Eval scores whether behavior was acceptable. NovaPilot turns recurring failure patterns into prioritized, specific, reviewable recommendations that teams can copy, test, and apply.
NovaPilot is not a dashboard feature. It is the missing step between a failed eval score and a decision about what to change.
The format of recommendations depends on what is being fixed. For prompt changes, NovaPilot generates a search-and-replace style output — a specific existing instruction and the suggested replacement, so engineers know exactly what to swap and where. For structural changes — orchestration logic, audio pipeline configuration, VAD thresholds, tool definitions — NovaPilot generates a narrative recommendation that explains the issue, the observed pattern, and the suggested direction, without pretending a text diff is the right format for a configuration or architecture change.
Internally, NovaPilot uses four specialized analysis agents:
| Analysis agent | Focus |
|---|---|
| Flow Analyzer | Agent execution flow, decision patterns, state transitions |
| Prompt Analyzer | Prompt quality, ambiguities, specific improvement suggestions |
| Tool Analyzer | Tool selection accuracy, parameter quality, result handling |
| General Analyzer | Cross-cutting failure patterns, statistical anomalies, run-over-run summary |
These agents collaborate on each eval run to produce recommendations, ranked by severity and frequency — not a flat list of everything that failed, but a prioritized view of what to fix first and why.
Before generating recommendations, NovaPilot also filters out false positives from scorer results. Because scorers are LLM-as-a-judge, they can occasionally misfire — flagging an item as a failure when the agent response was acceptable. NovaPilot runs a filtering pass before the report is assembled, so the recommendations engineers receive are based on confirmed failure patterns, not noise from scorer variance.
AI Agent Failure Patterns Auto-Analysis Can Turn Into Recommendations
| Failure pattern | What the eval detects | What manual debugging typically misses | What NovaPilot can generate or recommend |
|---|---|---|---|
| Hallucinated policy answer | Faithfulness scorer fails; retrieved context present but not used | Engineer checks the failing item, not the 40 others with the same retrieval query pattern | Specific system prompt suggestion to reinforce grounding; failure pattern grouped by query type |
| Prompt regression after model update | Instruction adherence or coherence score drops after model swap | Score drop is visible but which specific instruction the new model interprets differently requires a full audit — usually triggered only after the next incident | Revised prompt block targeting the regressed behavior; comparison against previous run |
| Tool called with wrong parameter | Tool correctness scorer fails on parameter accuracy | Caught eventually, but only if the reviewing engineer understands the tool’s expected parameter contract — which is rarely documented alongside the trace | Recommended prompt instruction clarifying parameter expectations |
| Multi-agent routing failure | Agent coordination scorer fails; wrong specialist receives task | Failure surfaces in the downstream agent’s scorer output — the routing decision that caused it is two spans upstream and easy to miss without cross-span analysis | Routing logic flag with failure pattern; suggested routing rule change |
| Repeated answer or loop | Coherence scorer fails; agent repeats previous output | Visible in a single trace but the memory or session-state condition that triggers it is rarely diagnosed across multiple items at once | Specific instruction suggestion for repetition detection |
| RAG answer not grounded in retrieved context | Contextual faithfulness or retrieval F1 scorer fails | Retrieval config and prompt grounding are both suspects — most engineers patch one without confirming whether the other is the actual cause | Grounding instruction block; scorer breakdown showing where faithfulness dropped |
| Voice agent speaks over user or ignores interruption | Speaking-over-user scorer fails (voice-specific scorer) | Voice failures are hard to review at scale — most teams catch these from user complaints, not systematic eval review across the full dataset | Flagged failure pattern with voice scorer details; recommended handling instruction |
| Safety refusal too broad or too weak | Safety scorer fails in either direction | Manual guardrail review is triggered by escalations, not by systematic detection of which query types are hitting the wrong refusal threshold | Refined safety instruction suggestion with specificity adjustment |
Why Final-Score Debugging Breaks Down in Multi-Agent Systems
Multi-agent failures are harder because the visible failure is often not the root cause. A response may fail at the final agent, while the actual issue started earlier in routing, handoff context, or state transition.
Consider a supervisor-specialist architecture. The supervisor receives a user query, classifies it, and routes to the appropriate specialist. If the supervisor's routing logic misclassifies a category — say, it routes a compliance question to the general knowledge agent instead of the compliance specialist — the downstream agent handles it with the wrong context and the wrong instructions. The final output fails. But the failure shows up in the final agent's trace, not the supervisor's.
If you are only looking at scorer output at the final step, you will patch the wrong agent.
This is where AI agent debugging needs observability, evaluation, and analysis to work together across spans, not just final outputs. For production teams, this multi-span view monitoring helps separate the visible failure from the actual root cause. Other common multi-agent failure modes where this matters:
- Downstream agent trusts an unverified assumption passed from the previous agent in the handoff context
- Two agents duplicate work because the coordination layer did not pass state correctly
- Handoff lacks required context — the receiving agent starts with an incomplete picture of what the user actually asked
- Invariant breaks mid-workflow — a constraint that was valid in step one is violated by step three because no agent checked it
- One patch fixes final output but worsens routing behavior — the fix works for the common case but degrades edge-case routing
In these scenarios, NovaPilot’s Flow Analyzer is designed to examine execution patterns and state transitions across the workflow — not just the final scorer result. Without multi-span context, teams risk fixing the symptom instead of the failure source.
What a Production-Ready Auto-Analysis Workflow Should Include
This checklist is useful regardless of which tooling you use. A workflow that skips any of these steps is producing recommendations that are not safe to act on.
Before the recommendation is generated:
- Trace-level evidence tied to the failure (not just a scorer score in isolation)
- Scorer output clearly linked to specific dataset items
- Root-cause hypothesis with the evidence that produced it
- Failure pattern grouping — is this one item or a recurring class?
During recommendation generation:
- Specific candidate fix (copyable prompt block, routing instruction, or parameter guidance)
- Evidence linking each recommendation to the specific dataset item IDs where the issue was observed — so engineers can verify the pattern themselves before acting on it
- Scenario-based testing against the failure class
- Comparison against baseline behavior — does this fix degrade passing cases?
- Regression check across related scorers, not just the one that failed
Before the team applies the fix:
- Human review of the recommendation and the evidence behind it
- Clear implementation path — what to change, where, and why
- Rollback plan if the fix causes a regression in production
- Post-merge monitoring configured to catch recurrence
NovaPilot Cron Jobs handles the last point automatically. Teams can schedule recurring eval runs on a daily, weekly, or custom cadence — NovaPilot generates a new report after each run, sends notifications on failure or completion, and maintains a run history so teams can track whether a fixed failure class reappears over time. The analysis does not require a manual trigger after every deployment.
Any tool that surfaces a recommendation without the first half of this checklist is handing you a guess dressed up as an insight.
Observability, Evaluation, and Auto-Analysis: Three Layers of Production AI Agent Monitoring
| Layer | What it answers | Example output | Where it stops |
|---|---|---|---|
| Observability | What happened? | Trace showing a tool call returned null, prompt context was 4,200 tokens, latency was 3.2s | It stops at the log. You know what occurred; you do not know if it was wrong or why. |
| Evaluation | Was it acceptable? | Faithfulness score: 0.31 (fail). Instruction adherence: 0.74 (pass). Tool correctness: fail on 14% of runs. | It stops at the score. You know it failed; you do not know what to change. |
| Auto-analysis | What should we fix, and how? | Failure pattern: 22 items failed faithfulness — all had retrieval queries about refund policy. Recommended: add grounding instruction to system prompt. Suggested block: [specific text]. | Should stop before deployment — the human reviews and applies the recommendation. |
Observability tells you what happened. Evaluation tells you whether it was acceptable. Auto-analysis helps turn that evidence into a specific, testable change.
The gap between the second and third rows is where most teams spend their unplanned engineering time.
How Production Teams Should Validate AI Agent Fixes
Auto-analysis that earns trust does not remove engineering judgment. It compresses the debugging loop.
The difference is meaningful. Without an analysis layer, an engineer gets a scorer output, a trace, and a blank prompt editor. With a credible analysis layer, that same engineer gets a specific recommendation, the failure pattern that produced it, and a suggested prompt block they can test in ten minutes instead of two hours.
The engineer still decides whether the recommendation is correct. They still run the test. They still approve before anything changes in production. The analysis layer is a starting point, not a conclusion.
For teams evaluating any auto-analysis tooling, the control surface to look for:
- PR-based or review-based workflows — changes should go through the same approval process as any other code change
- Auditability — every recommendation should trace back to the eval results and failure patterns that produced it
- Environment separation — recommendations should be testable in staging before any production change
- No silent production mutation — any tool that applies changes to production without an approval gate is a risk, not a feature
- Approval gates tied to severity — a minor coherence issue and a safety scorer failure should not go through the same level of review
The goal is to make the debugging loop faster and more systematic — not to replace the engineers who understand the production system.
How Noveum Closes the Gap Between Failed Evals and Fixes
Most observability and evaluation platforms stop at "here is what failed." Noveum is built around "here is what failed, why it failed, and the specific change worth testing first." That distinction matters most for teams doing production AI agent monitoring at scale, where a failed eval queue compounds faster than an engineer can manually debug it.
Noveum Trace captures behavior at the span level — every LLM call, tool use, agent decision, and token, at 6M traces per day.
Nova Eval scores behavior across 100+ specialized scorers in 18 evaluation categories, including 17 voice/audio scorers and a full RAG evaluation suite. Custom scorers can be built from a client's own PRD requirements — not generic templates.
NovaPilot is the analysis layer on top of eval results. It groups failures by pattern, prioritizes by severity and frequency, and generates specific prompt suggestions — including copyable system prompt blocks — that teams can test immediately and compare against the previous run. NovaPilot also supports scheduled quality monitoring through Cron Jobs, so the analysis runs automatically rather than requiring manual triggering after every deployment.
NovaSynth generates synthetic personas and test scenarios so teams can surface failure classes before real users encounter them — not just after.
The practical difference from observability-only or evaluation-only platforms: Langfuse shows you logs. Arize surfaces traces and dashboards. Braintrust runs experimentation evals. None of them generate a specific, prioritized, evidence-backed recommendation for what to change next.
NovaPilot is the analyst layer that most eval platforms do not include.
The Bottom Line for Production AI Teams
If your eval suite is running and you can see what broke, you have already solved the hard infrastructure problem. But seeing what broke is not the same as knowing what to change.
The post-eval debugging loop — from scorer output to root cause to tested fix to reviewed recommendation — is where production AI teams lose most of their unplanned engineering time. The tools that stop at the dashboard are not wrong. They are just incomplete.
If your evals already tell you what broke, the next question is whether your system can help you understand why it broke and what to test first. NovaPilot is Noveum's answer to that gap.
If that gap already exists in your agent workflow, you should book a NovaPilot demo.
Frequently Asked Questions (FAQ)
What Is AI Agent Debugging — and What Should Auto-Fix Actually Mean?
AI agent debugging is the process of moving from a flagged failure — a failed scorer, a bad trace, a repeated error class — to a specific, tested change in production. In practice, most teams do this manually: open the trace, form a hypothesis, patch the prompt, retest, open a PR. In the context of production AI agents, auto-fix refers to a workflow that compresses that debugging loop by generating specific, testable recommendations for what to change. A credible auto-fix or auto-analysis system detects failure patterns from eval results, identifies the likely root cause, and produces reviewable recommendations — such as revised system prompt blocks or routing instruction changes — that engineering teams can test and apply. It should not mean autonomous deployment of changes to production without human review.
How is auto-analysis different from AI agent evaluation?
Evaluation scores agent behavior — it tells you whether a response was faithful, whether a tool was called correctly, whether an answer hallucinated. Auto-analysis reads those scores and goes further: it groups failures by pattern, identifies the probable cause, and generates a specific recommendation for what to fix. Evaluation answers "did it fail?" Auto-analysis answers "what should we change?"
Is it safe to let AI generate fix recommendations for production agents?
With the right controls, yes. The key is keeping engineers in the approval loop. Recommendations should be reviewable, testable in a non-production environment, and traceable back to the eval evidence that produced them. Any system that applies changes to production without a human approval step is not a safe auto-fix workflow — it is an autonomous deployment risk.
What kinds of AI agent failures can NovaPilot help with?
NovaPilot analyzes failures surfaced by Nova Eval scorers, which cover hallucination, faithfulness, RAG grounding, tool correctness, instruction adherence, safety, multi-agent coordination, voice quality, and more. It can recommend prompt changes for failures like hallucinated answers, prompt regressions after model updates, tool parameter errors, routing failures in multi-agent systems, and grounding failures in RAG pipelines.
Does auto-analysis replace ML engineers?
No. Auto-analysis compresses the debugging loop — it reduces the time between a flagged failure and a testable fix recommendation. Engineers still review the recommendation, validate it against their understanding of the production system, run the tests, and approve before deployment. The analysis layer handles the pattern detection and hypothesis generation; the engineer handles the judgment and the deployment decision.
How does auto-analysis work for multi-agent systems?
Multi-agent failures are harder because a failure that surfaces in one agent often originates in a different span — a routing decision, a handoff, or a shared context problem upstream. NovaPilot's Flow Analyzer is designed to examine execution patterns and state transitions across spans, not just final scorer output. This matters for failures like incorrect routing by a supervisor agent, missing context in a handoff, or an invariant that breaks mid-workflow.
Can auto-analysis help with prompt regressions after a model update?
Yes. Prompt regressions are a common failure class after model swaps — instruction adherence or coherence scores drop because the new model interprets instructions differently than the previous one. NovaPilot can detect this pattern across eval runs, compare current scores against previous run baselines, and generate revised prompt blocks targeted at the regressed behavior.
What should teams check before applying an auto-generated fix recommendation?
Before applying any recommendation, teams should verify: (1) the failure pattern is real and recurring, not a single-item anomaly; (2) the recommendation traces back to specific eval evidence, not a generic heuristic; (3) the suggested change has been tested against the failure class and checked for regressions on previously passing cases; (4) the change is reviewed by someone who understands the production system; and (5) post-merge monitoring is in place to catch recurrence. Recommendations without this backing are guesses, not analysis.
Get Early Access to Noveum.ai Platform
Join the select group of AI teams optimizing their models with our data-driven platform. We're onboarding users in limited batches to ensure a premium experience.