GPT-OSS vs GPT-5 vs GPT-4o-mini — MMLU Benchmark Comparison (Accuracy, Runtime, Thinking Modes)

Shivam Gupta
Generated on: 2025-08-13
This report is a plain-English summary of how seven model setups perform on the MMLU benchmark across 10 subjects (about 500 questions each). We compare:
- accuracy (who gets the most answers right)
- speed/runtime (how fast the models finish)
- the impact of GPT-OSS “thinking modes” (low, medium, high, unspecified) on results and efficiency
Use this to quickly choose the model or mode that best fits your needs—fastest, most accurate, or most consistent.
TL;DR
- Most accurate: GPT-5 (91.38%)
- Best speed/efficiency: GPT-OSS (low thinking mode)
- Best balance (accuracy + runtime): O3 or GPT-OSS (medium thinking mode)
1. Overall Model Performance
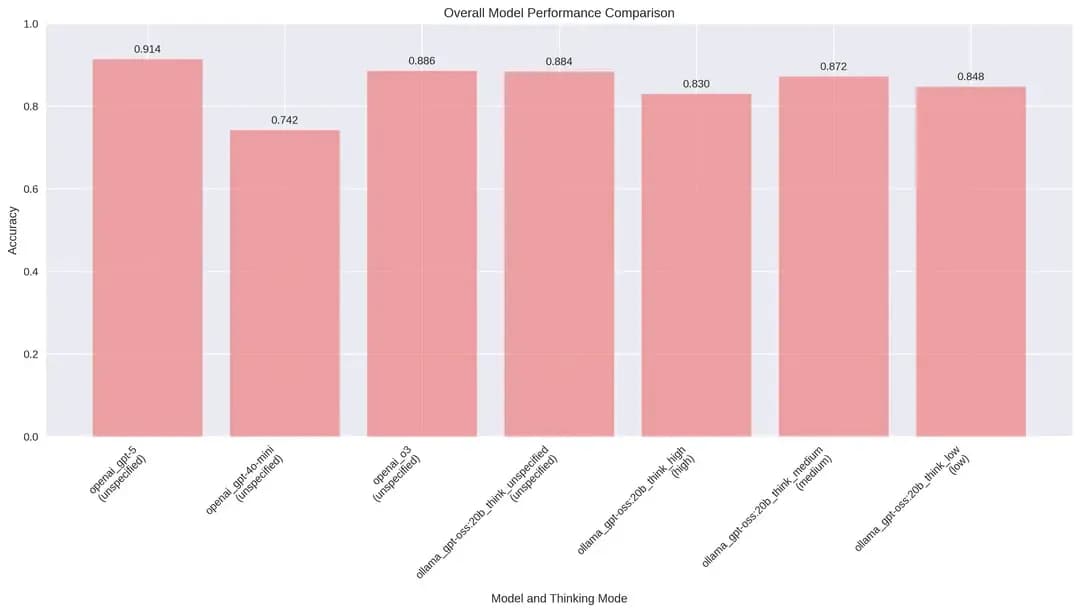
The evaluation tested 7 model configurations across different thinking modes, revealing significant performance variations and the impact of reasoning strategies:
| Model | Accuracy | Questions | Performance Rank | Thinking Mode |
|---|---|---|---|---|
| GPT-5 (OpenAI) | 91.38% | 500 | 1st | unspecified |
| O3 (OpenAI) | 88.60% | 500 | 2nd | unspecified |
| GPT-OSS (unspecified) | 88.40% | 500 | 3rd | unspecified |
| GPT-OSS (medium) | 87.20% | 500 | 4th | medium |
| GPT-OSS (low) | 84.77% | 499 | 5th | low |
| GPT-OSS (high) | 83.00% | 500 | 6th | high |
| GPT-4o-mini (OpenAI) | 74.20% | 500 | 7th | unspecified |
Performance Insights:
- Clear leader: GPT-5 tops accuracy (91.38%)
- Strong contenders: O3 (88.60%) and GPT-OSS (unspecified: 88.40%)
- Long tail: GPT-4o-mini trails at 74.20%
- Gap: 17.18pp between first and last
2. Subject-Wise Performance Analysis
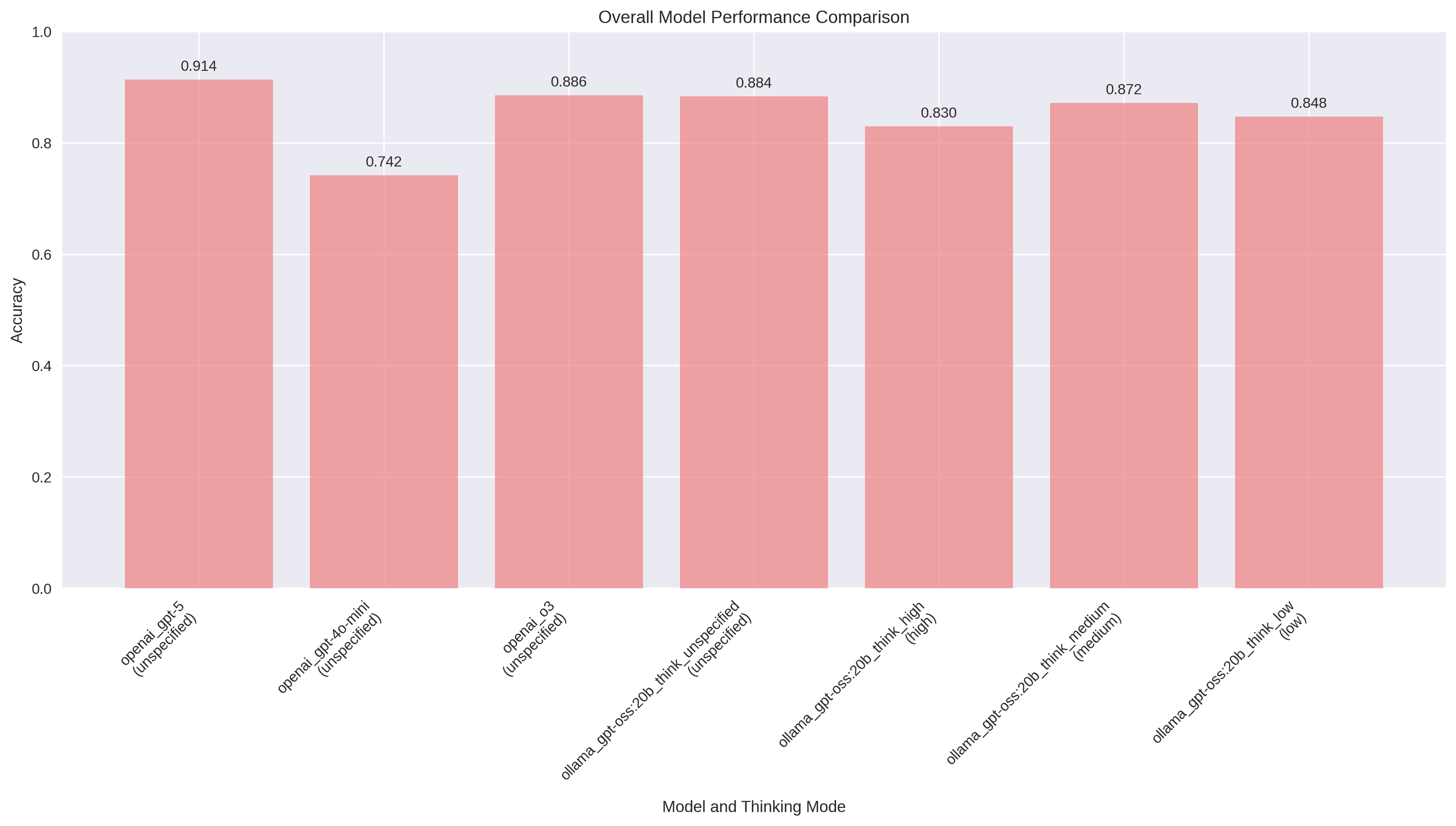
The evaluation covered 10 academic subjects, revealing subject-specific strengths and weaknesses across all models:
Top Performing Subjects
- Elementary Mathematics: 95.71% average accuracy
- College Physics: 94.29% average accuracy
- Conceptual Physics: 90.57% average accuracy
Most Challenging Subjects
- College Chemistry: 63.63% average accuracy
- College Mathematics: 81.43% average accuracy
- High School Mathematics: 83.69% average accuracy

Subject Difficulty Analysis:
- Hardest: College Chemistry (36.37% difficulty)
- Easiest: Elementary Mathematics (4.29% difficulty)
- Pattern: Physics stays strong; advanced math varies by model
Subject-Specific Performance Patterns:
Abstract Algebra: GPT-OSS models dominate the top 2 positions, with both high and medium thinking modes achieving 92% accuracy. This suggests that GPT-OSS excels at mathematical reasoning tasks when given appropriate thinking parameters.
College Chemistry: All models struggle, with GPT-5 performing best at 71.43%. The subject shows the highest variability, indicating fundamental challenges in chemical reasoning that persist across all thinking strategies.
College Mathematics: O3 leads with 94% accuracy, followed closely by GPT-5. GPT-OSS models show consistent performance around 88%, suggesting good mathematical capabilities regardless of thinking mode.
Physics Subjects: Both college and conceptual physics show strong performance across models, with GPT-OSS low thinking mode achieving perfect scores in college physics, indicating efficient reasoning for physics problems.
Elementary Mathematics: All models perform exceptionally well (94%+), with GPT-5 leading at 98%. This suggests that basic mathematical reasoning is well-handled by all models.
3. Thinking Mode Effects Analysis
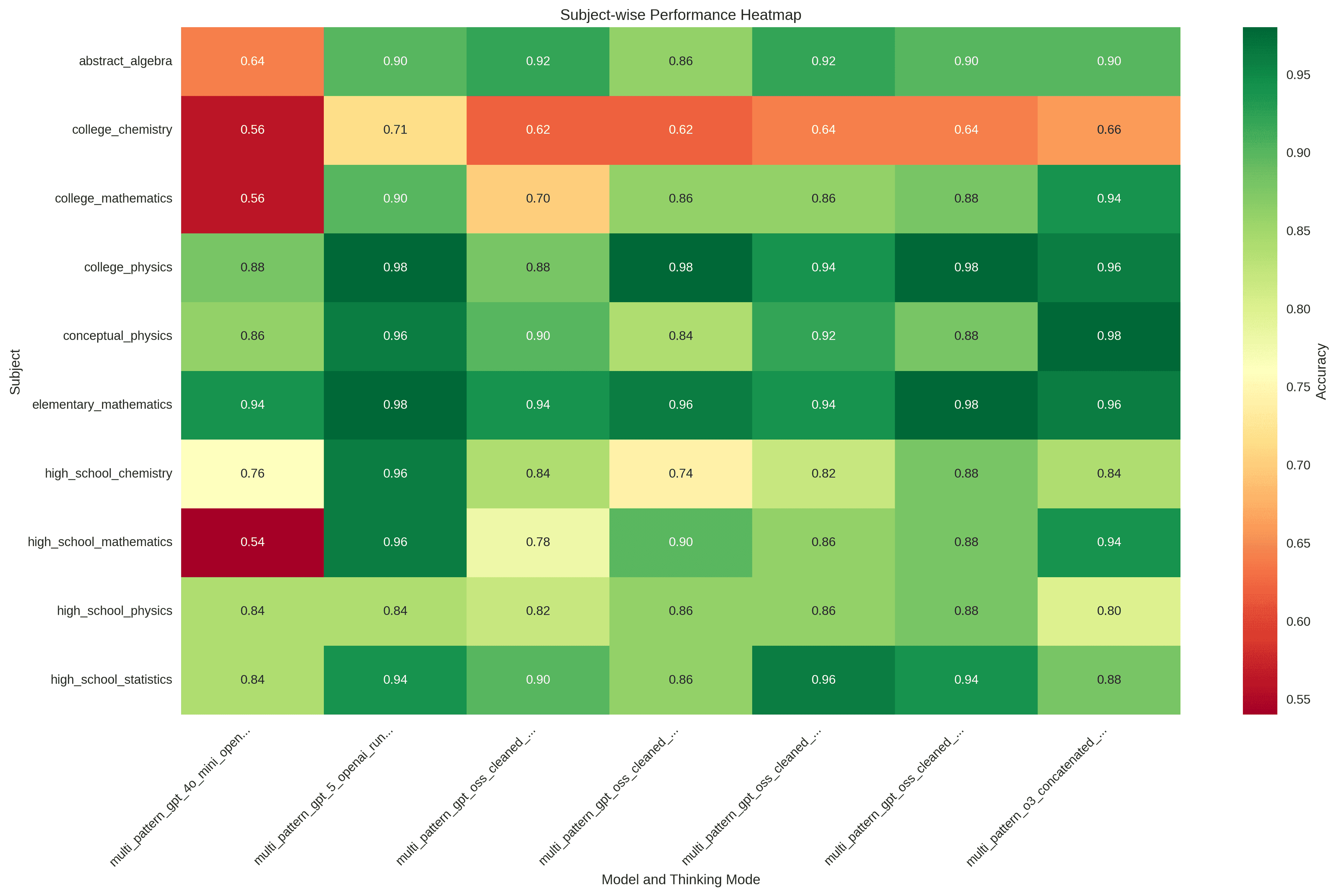
The GPT-OSS model was tested across four thinking modes using an A100 40GB GPU, revealing critical insights into the relationship between reasoning depth and performance:
Thinking Mode Performance Comparison
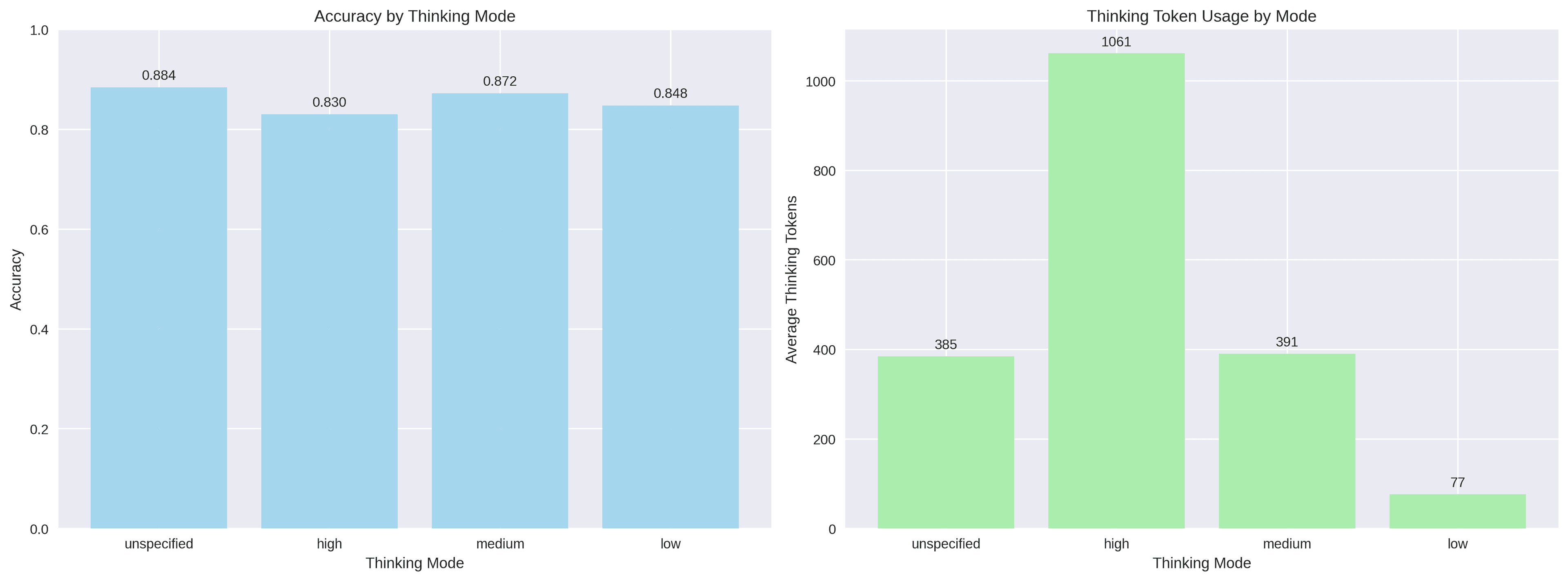
| Mode | Accuracy | Avg Thinking Tokens | GPU Runtime | Efficiency |
|---|---|---|---|---|
| Unspecified | 88.40% | 384.60 ± 532.24 | 135.57s | Best Balance |
| Medium | 87.20% | 390.57 ± 570.66 | 138.42s | Most Efficient |
| Low | 84.77% | 76.55 ± 84.97 | 57.49s | Most Runtime-Efficient |
| High | 83.00% | 1061.48 ± 1311.63 | 279.54s | Least Efficient |
Key Insights:
- Low mode = fastest good-enough results (best runtime/accuracy tradeoff)
- Medium mode = balanced choice for most workloads
- Unspecified = highest accuracy within GPT-OSS, with extra runtime
- High mode = slowest and often worse; use only for niche deep-reasoning cases
Runtime-Performance Trade-offs:
- Low mode: 0.68 seconds per percentage point of accuracy
- Medium mode: 1.59 seconds per percentage point of accuracy
- Unspecified mode: 1.53 seconds per percentage point of accuracy
- High mode: 3.37 seconds per percentage point of accuracy
4. Token Usage and Efficiency
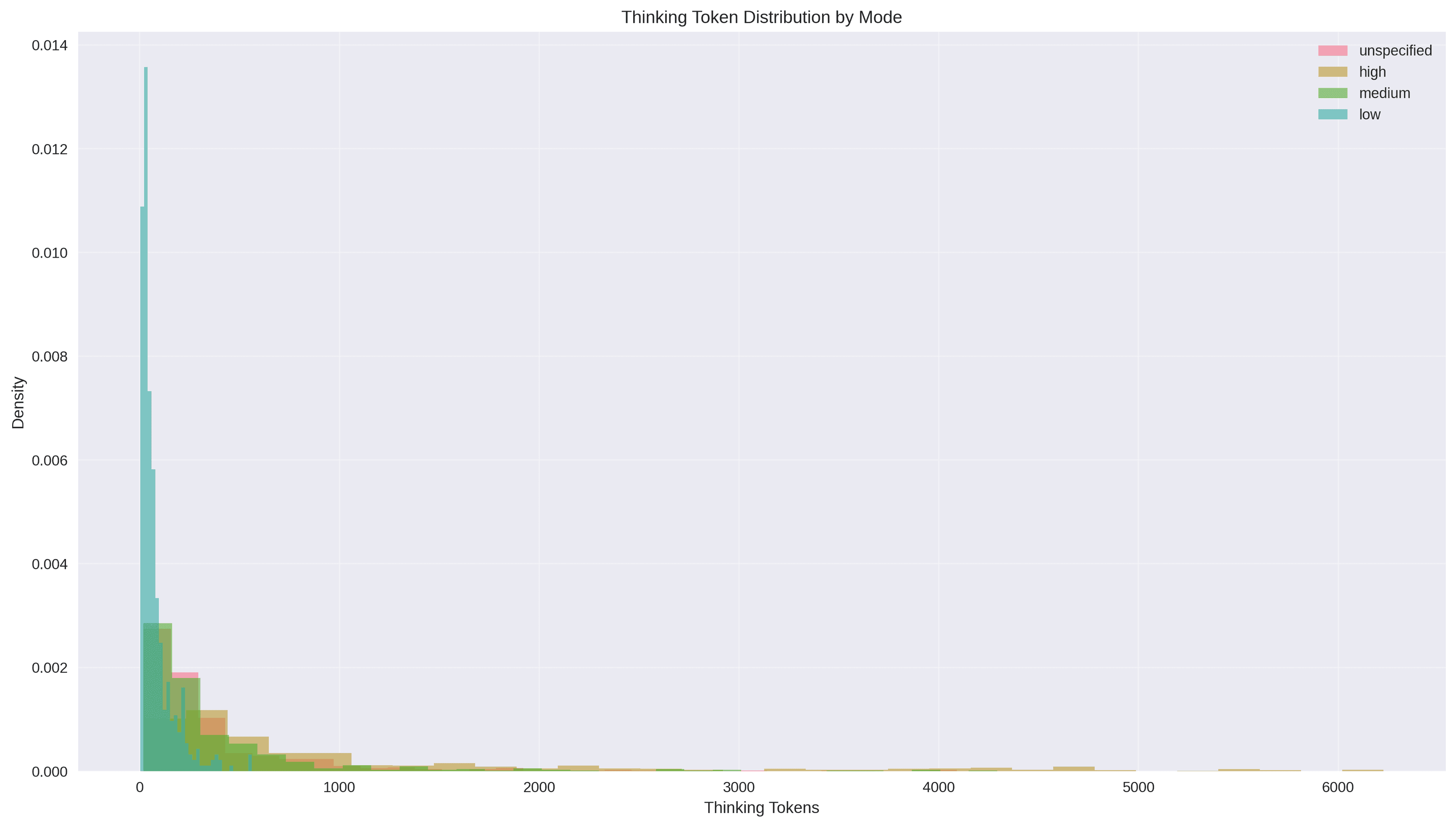
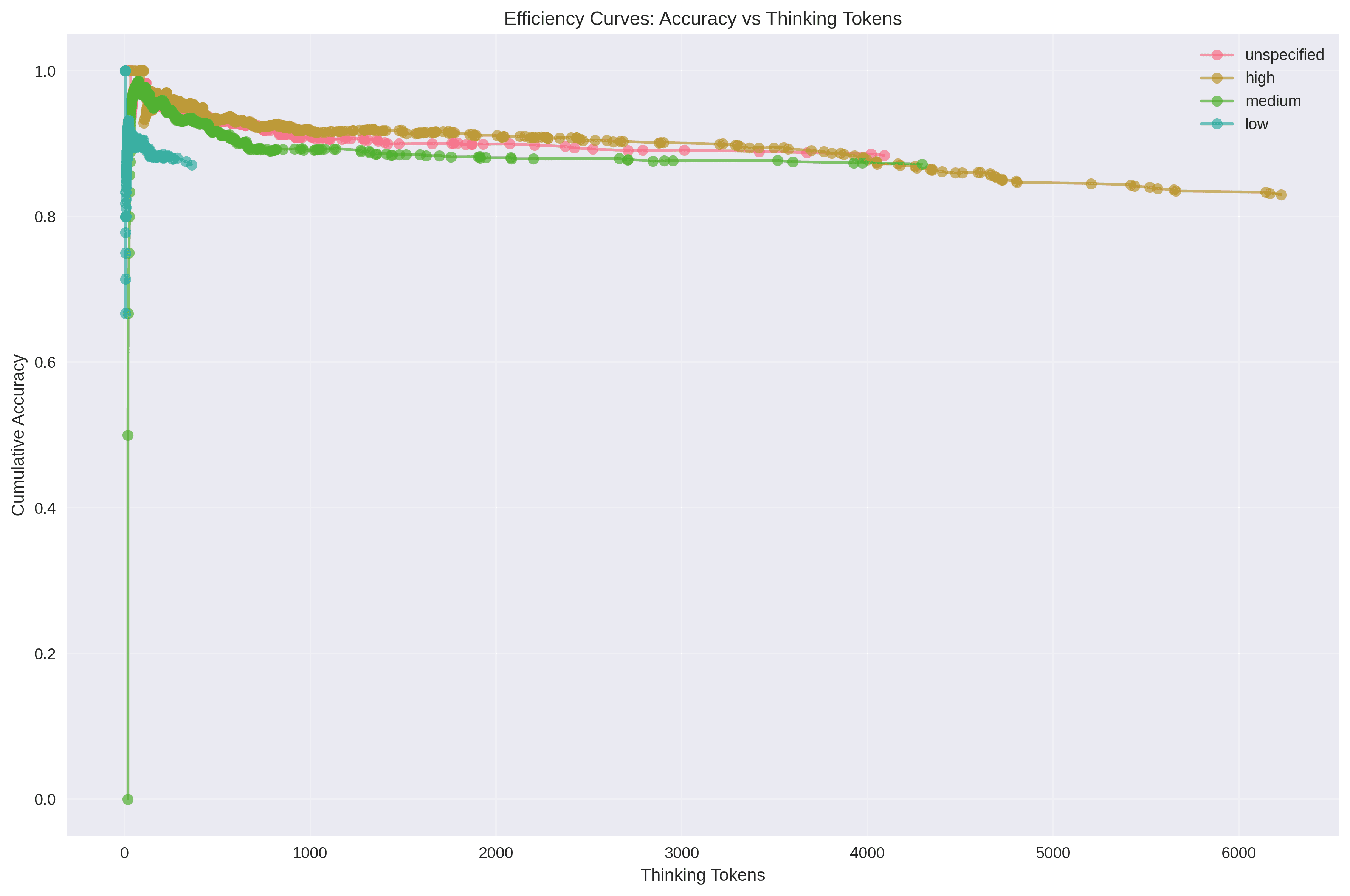
Efficiency Curves
- Low mode: Best at 2–59 tokens (~90%); noticeable drop beyond 170 tokens
- Medium mode: Broad sweet spot 15–446 tokens (~92.65%); balanced overall
- High mode: Diminishing returns; accuracy declines past ~2500 tokens
- Unspecified: Reliable 17–428 tokens (~93.77%); steady decline with complexity
5. Runtime vs Accuracy
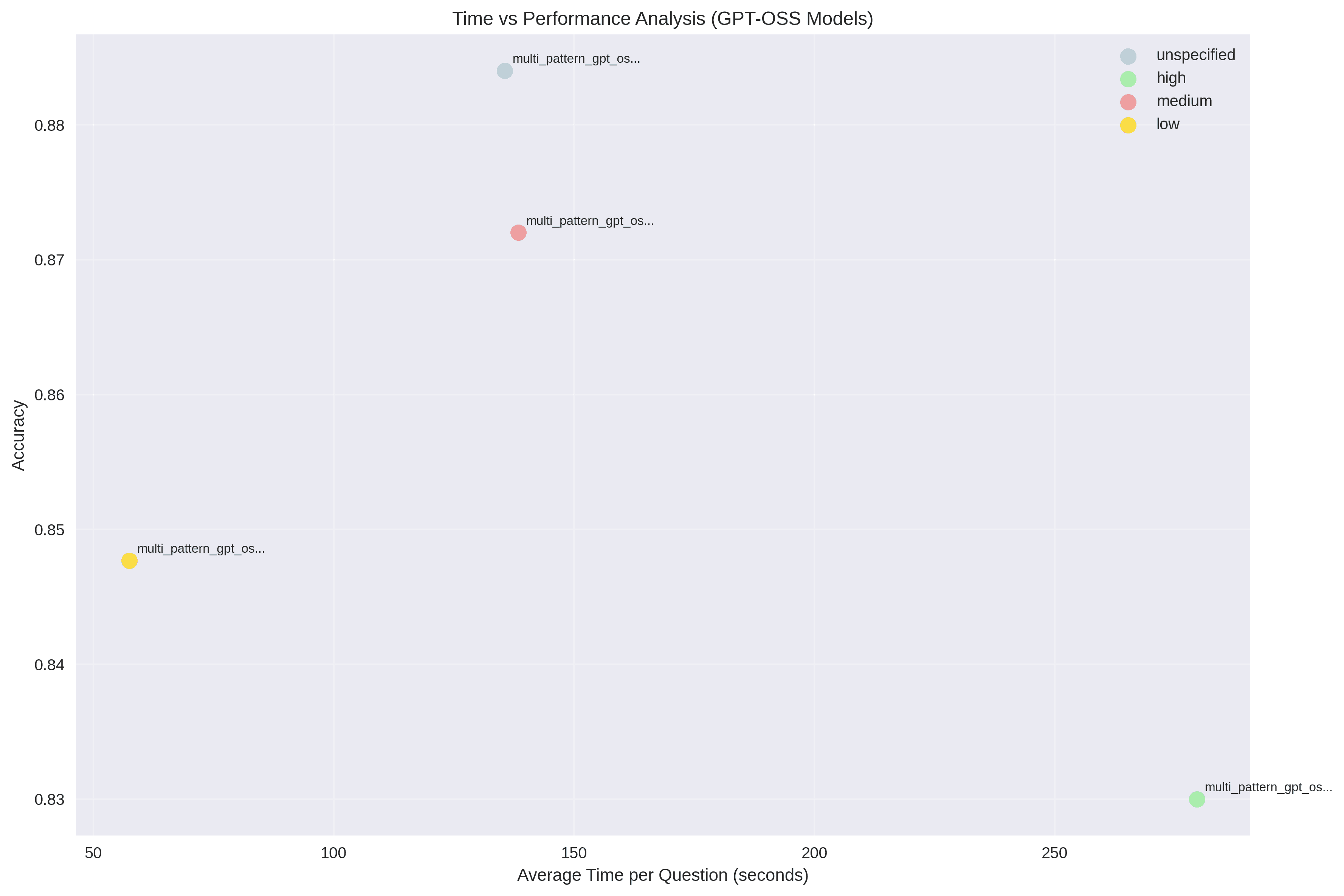
Runtime-Effectiveness Rankings
- Low Thinking Mode: 57.49s for 84.77% accuracy
- Runtime per percentage point: 0.68s
- Best value proposition for time-sensitive applications
- Medium Thinking Mode: 138.42s for 87.20% accuracy
- Runtime per percentage point: 1.59s
- Good balance of performance and runtime
- Unspecified Mode: 135.57s for 88.40% accuracy
- Runtime per percentage point: 1.53s
- Premium performance at higher runtime cost
- High Thinking Mode: 279.54s for 83.00% accuracy
- Runtime per percentage point: 3.37s
- Least efficient option
Runtime-Performance Insights:
- Best ROI: Low mode
- Best balance: Medium mode
- Premium accuracy: Unspecified
- Avoid: High mode unless required
How to choose (quick guide)
- Max accuracy: Choose GPT-5
- Speed/cost-sensitive: Choose GPT-OSS with thinking mode = low
- Balanced: Choose O3 or GPT-OSS with thinking mode = medium
- Chemistry-heavy workloads: Validate on your data; consider domain-tuned models
6. Consistency (Subject Variance)
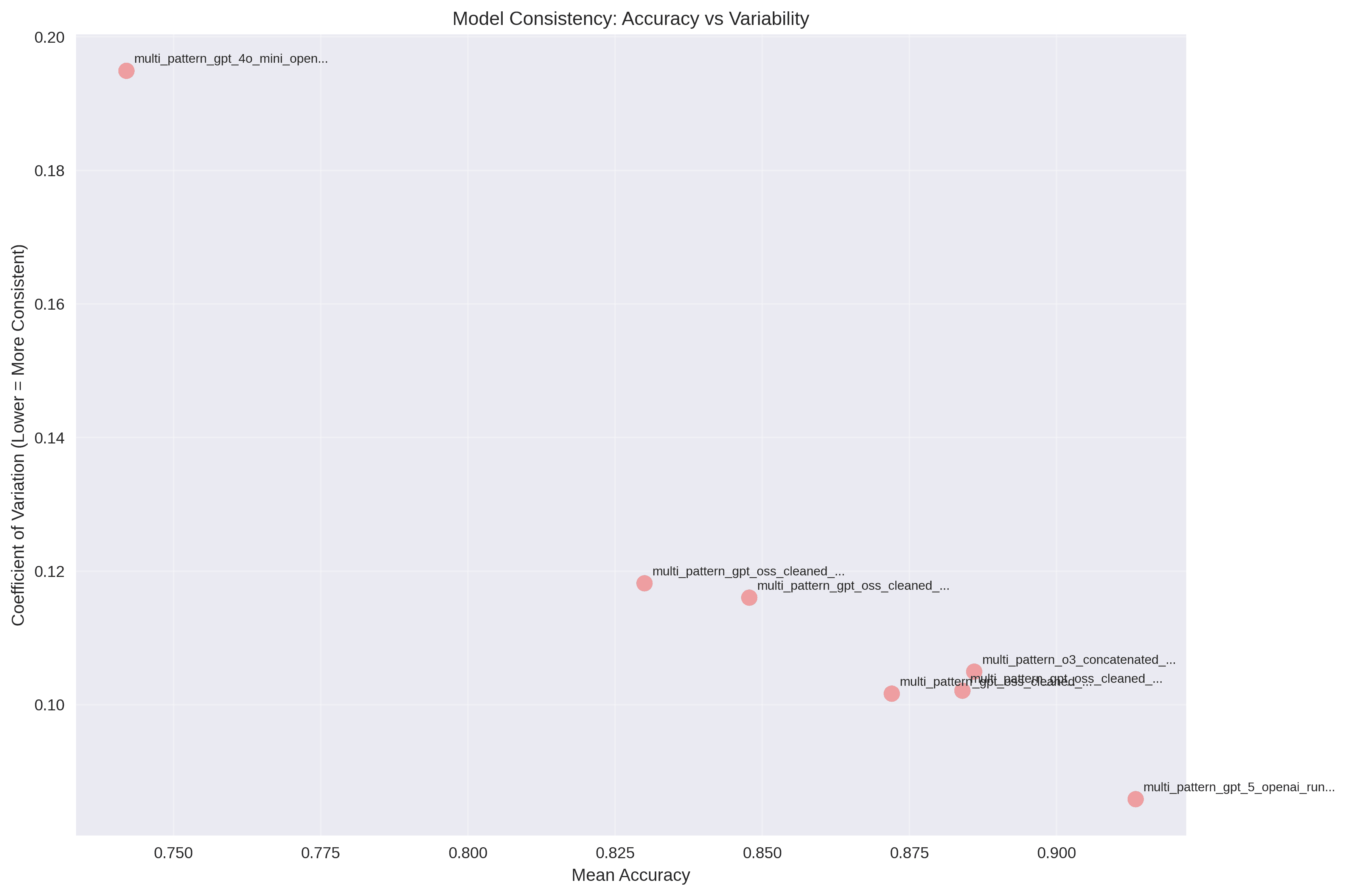
Consistency Rankings (Lower CV = More Consistent)
| Model | Mean Accuracy | CV | Consistency Rank |
|---|---|---|---|
| GPT-5 (OpenAI) | 91.34% | 8.58% | Most Consistent |
| GPT-OSS Medium | 87.20% | 10.16% | 2nd |
| GPT-OSS Unspecified | 88.40% | 10.21% | 3rd |
| O3 (OpenAI) | 88.60% | 10.49% | 4th |
| GPT-OSS Low | 84.78% | 11.60% | 5th |
| GPT-OSS High | 83.00% | 11.82% | 6th |
| GPT-4o-mini | 74.20% | 19.49% | Least Consistent |
Consistency Insights:
- GPT-5 shows remarkable consistency across subjects despite high performance
- GPT-4o-mini exhibits high variability, suggesting subject-specific weaknesses
- GPT-OSS models show moderate consistency with thinking mode effects
- O3 model shows competitive performance (88.60%) with moderate consistency, positioning it as a strong alternative to GPT-5
7. Thinking Tokens vs Accuracy
Thinking Token vs. Accuracy Correlations
All GPT-OSS models show negative correlations between thinking tokens and accuracy:
- High Mode: -0.56 (strongest negative correlation)
- Unspecified Mode: -0.38 (moderate negative correlation)
- Medium Mode: -0.27 (moderate negative correlation)
- Low Mode: Insufficient data for correlation (most responses use minimal tokens)
Interpretation:
- More thinking tokens correlate with lower accuracy
- This suggests that simpler, more direct reasoning lead to better performance
- Complex reasoning may introduce errors or overthinking
- The relationship is consistent across all thinking modes for GPT-OSS 20B
- High thinking mode shows the strongest negative correlation, indicating the most significant performance degradation with increased complexity
8. Outliers (College Chemistry)
Subject Outlier: College Chemistry
- Z-score: -2.5354 (statistically significant outlier)
- Mean Accuracy: 63.63%
- Outlier Type: Low performer
Analysis:
- College Chemistry shows significantly lower performance than expected
- All models struggle with this subject, suggesting fundamental challenges
- GPT-5 performs best at 71.43%, but even this is not good
- The subject may require specialized knowledge or reasoning patterns not well-represented in the training data
- Thinking mode variations show minimal impact, indicating the challenge is fundamental rather than reasoning-strategy dependent
9. Recommendations
For Production Use
- Runtime-Sensitive Applications: Use GPT-OSS with low thinking mode for best speed-accuracy ratio
- Performance-Critical Applications: Use GPT-5 for maximum accuracy and consistency
- Balanced Applications: Use O3 for high performance with moderate runtime, or GPT-OSS with medium thinking mode
- Enterprise Applications: Consider O3 as a cost-effective alternative to GPT-5 when 88.6% accuracy is sufficient
For Research and Development
- Consistency Studies: Focus on GPT-5 model for stable performance across subjects
- Efficiency Optimization: Study low thinking mode patterns for runtime reduction
- Subject-Specific Tuning: Develop specialized models for challenging subjects like Chemistry
- Thinking Mode Research: Investigate why high thinking modes show performance degradation
For Model Selection
- Academic Applications: Prioritize GPT-5 for comprehensive coverage, with O3 as a strong alternative
- Resource-Constrained Environments: Choose GPT-OSS low thinking mode
- Real-Time Applications: Consider medium thinking mode for speed-accuracy balance
- Enterprise Deployments: O3 offers an excellent balance of performance (88.6%) and runtime efficiency
10. Limitations and Future Work
Current Limitations
- All models have consistent sample sizes (approximately 500 questions each)
- Single evaluation run per model configuration
- Focus on GPT-OSS thinking modes only
- Limited subject coverage (10 out of 57 MMLU subjects)
- Runtime measurements based on A100 40GB GPU performance
Future Research Directions
- Extended Subject Coverage: Evaluate all 57 MMLU subjects
- Multiple Runs: Assess model consistency across multiple evaluations
- Thinking Mode Optimization: Develop adaptive thinking mode selection based on problem complexity
- Runtime Analysis: Include latency and throughput metrics across different GPU configurations
- Cross-Model Comparison: Evaluate thinking modes across different model architectures
- Performance Degradation Study: Investigate why high thinking modes show worse performance
Conclusion
This comprehensive MMLU evaluation provides critical insights into model performance, efficiency, and runtime characteristics across different thinking strategies. Key takeaways include:
- GPT-5 remains the performance leader with excellent consistency (91.38% accuracy, 8.58% CV)
- O3 emerges as a strong competitor with 88.6% accuracy, offering enterprise-grade performance
- GPT-OSS offers excellent runtime-performance ratios across different thinking modes
- Low thinking mode provides the best value for GPU runtime (57.49s for 84.77% accuracy)
- Subject difficulty varies significantly, with Chemistry being most challenging (36.37% difficulty)
- Model consistency varies widely, with GPT-5 showing remarkable stability
- Thinking token efficiency shows that simpler reasoning often leads to better performance
- High thinking modes show performance degradation, challenging the assumption that more complex reasoning improves results
Key takeaways:
- GPT-5 leads in accuracy and consistency (91.38%, CV 8.58%)
- O3 is a strong, fast alternative (88.6%)
- GPT-OSS (low mode) delivers the best speed/accuracy tradeoff
- Chemistry is hardest; validate domain-specific workloads
- More tokens ≠ better: excessive thinking often reduces accuracy
Practical implication: prefer simpler, focused reasoning by default; scale up thinking depth only when problems demand it.
Report generated from MMLU evaluation data covering 7 model configurations, 4 thinking modes, and 10 academic subjects across approximately 500 total samples per model. GPU runtime measurements based on A100 40GB GPU performance. Analysis generated on 2025-08-13.
Get Early Access to Noveum.ai Platform
Join the select group of AI teams optimizing their models with our data-driven platform. We're onboarding users in limited batches to ensure a premium experience.