From Development to Production - Inside Noveum.ai's AI Observability Platform

Shashank Agarwal
Introduction
Every AI application tells a story—but most developers never get to hear it. When your RAG pipeline returns irrelevant results, when your multi-agent system gets stuck in loops, or when your LLM costs suddenly spike, you're left guessing what went wrong and where.
That's exactly the challenge Noveum.ai solves. Rather than flying blind, our platform provides comprehensive tracing and observability specifically designed for AI applications. Whether you're building LLM-powered chatbots, RAG systems, or complex multi-agent workflows, Noveum.ai gives you the insights you need to understand, debug, and optimize your AI applications.
The AI Observability Challenge
Why Traditional Monitoring Falls Short
Traditional application monitoring tools weren't built for AI applications. They can tell you if your API is responding, but they can't answer the questions that matter most for AI systems:
- Why did my RAG pipeline retrieve irrelevant documents?
- Which LLM calls are driving my costs?
- How are my agents communicating with each other?
- What's causing hallucinations in my responses?
- Why is my embedding generation so slow?
What Makes AI Applications Different
AI applications have unique characteristics that require specialized observability:
- 🧠 Context Flow: Data flows through embeddings, retrievals, and generations
- 💰 Variable Costs: Token usage creates unpredictable expenses
- 🔀 Complex Workflows: Multi-step pipelines with branching logic
- 🤖 Agent Interactions: Multiple AI entities coordinating tasks
- 📊 Quality Metrics: Success isn't just about uptime—it's about output quality
Step 1: SDK Integration
Effortless Instrumentation
At the heart of Noveum.ai are our Python and TypeScript SDKs that integrate seamlessly into your existing codebase. With just a few lines of code, you can start capturing comprehensive traces of your AI operations.
<Tabs defaultValue="python"> <TabsList> <TabsTrigger value="python">🐍 Python</TabsTrigger> <TabsTrigger value="typescript">📘 TypeScript</TabsTrigger> </TabsList> <TabsContent value="python">import noveum_trace
# Initialize once at startup
noveum_trace.init(
api_key="your-api-key",
project="customer-support-bot",
environment="production"
)
# Trace LLM calls automatically
@noveum_trace.trace_llm
def generate_response(user_question: str) -> str:
return openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": user_question}]
).choices[0].message.content
import { initializeClient, trace } from '@noveum/trace';
// Initialize once at startup
const client = initializeClient({
apiKey: 'your-api-key',
project: 'customer-support-bot',
environment: 'production',
});
// Trace operations automatically
const generateResponse = trace('llm-completion', async (userQuestion: string) => {
return await openai.chat.completions.create({
model: 'gpt-4',
messages: [{ role: 'user', content: userQuestion }],
});
});
What Gets Captured Automatically
Once integrated, Noveum.ai automatically captures:
- 🔍 Request/Response Data: Inputs, outputs, and transformations
- ⏱️ Performance Metrics: Latency, throughput, and bottlenecks
- 💰 Cost Tracking: Token usage and API costs across providers
- 🏷️ Rich Metadata: Model parameters, user context, and custom attributes
- 🌊 Context Flow: How data moves through your AI pipeline
- 🐛 Error Details: Stack traces and failure analysis
Step 2: Understanding Your AI Workflows
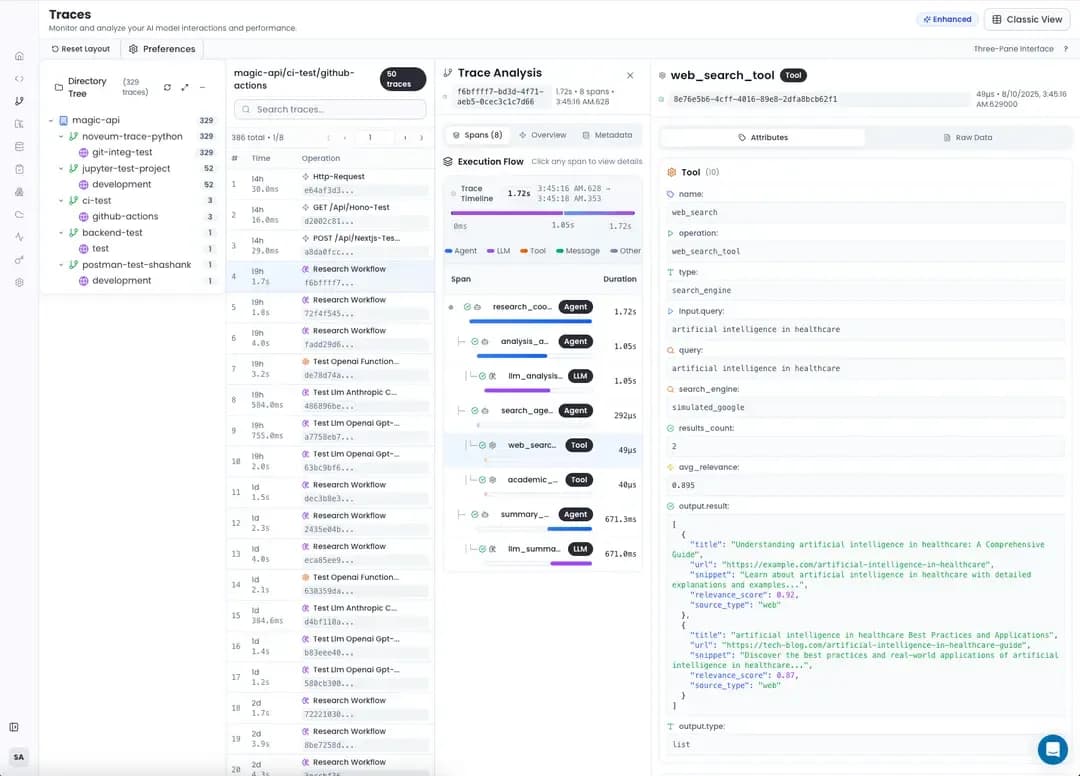
RAG Pipeline Visibility
RAG (Retrieval-Augmented Generation) systems involve multiple complex steps. Noveum.ai traces each phase, giving you complete visibility:
@noveum_trace.trace("rag-pipeline")
def answer_customer_question(question: str) -> str:
# Phase 1: Query understanding
with noveum_trace.trace_step("query-analysis") as step:
intent = analyze_query_intent(question)
step.set_attribute("query.intent", intent)
step.set_attribute("query.complexity", get_complexity_score(question))
# Phase 2: Document retrieval
with noveum_trace.trace_step("document-retrieval") as step:
embeddings = generate_embeddings(question)
documents = vector_search(embeddings, k=5)
step.set_attribute("documents.retrieved", len(documents))
step.set_attribute("documents.avg_similarity", avg_similarity(documents))
step.set_attribute("retrieval.model", "text-embedding-ada-002")
# Phase 3: Answer generation
with noveum_trace.trace_step("answer-generation") as step:
context = build_context(documents)
answer = generate_answer_with_context(question, context)
step.set_attribute("context.length", len(context))
step.set_attribute("answer.confidence", calculate_confidence(answer))
step.set_attribute("generation.model", "gpt-4")
return answer
Multi-Agent Coordination
When multiple AI agents work together, Noveum.ai tracks their interactions and coordination:
const multiAgentTask = trace('customer-inquiry-resolution', async (inquiry: string) => {
// Agent 1: Classification
const category = await span('classify-inquiry', async (spanInstance) => {
spanInstance.setAttribute('agent.name', 'classifier');
spanInstance.setAttribute('inquiry.length', inquiry.length);
return await classificationAgent.categorize(inquiry);
});
// Agent 2: Research (if needed)
let context = null;
if (category.needsResearch) {
context = await span('research-context', async (spanInstance) => {
spanInstance.setAttribute('agent.name', 'researcher');
spanInstance.setAttribute('research.category', category.type);
return await researchAgent.gatherContext(inquiry);
});
}
// Agent 3: Response generation
const response = await span('generate-response', async (spanInstance) => {
spanInstance.setAttribute('agent.name', 'responder');
spanInstance.setAttribute('response.has_context', !!context);
return await responseAgent.generate(inquiry, context);
});
return response;
});
Step 3: Real-Time Debugging and Optimization
Performance Bottleneck Identification
Noveum.ai's dashboard automatically identifies performance issues:
- 🐌 Slow Operations: Which LLM calls or embeddings are taking too long?
- 🔄 Redundant Processing: Are you generating the same embeddings multiple times?
- 📊 Resource Usage: Which operations consume the most tokens or memory?
- 🚨 Error Patterns: What types of failures occur most frequently?
Cost Optimization Insights
With detailed cost tracking, you can optimize your AI spending:
- Provider Comparison: See actual costs across OpenAI, Anthropic, Google, etc.
- Model Analysis: Compare performance vs. cost for different models
- Usage Patterns: Identify expensive operations and optimize them
- Budget Alerts: Get notified when costs exceed thresholds
Quality Assurance
Beyond performance, Noveum.ai helps ensure output quality:
- Response Analysis: Track confidence scores and quality metrics
- A/B Testing: Compare different models or prompts
- User Feedback: Correlate user satisfaction with trace data
- Drift Detection: Identify when model performance degrades
Real-World Example: Customer Support Bot
Let's walk through a real example. You've built a customer support bot using RAG that helps users with product questions. Here's how Noveum.ai provides insights:
Development Phase
During development, you discover through tracing that:
- Embedding generation takes 200ms on average
- Vector search finds relevant documents 85% of the time
- Answer generation costs $0.02 per query with GPT-4
Production Deployment
In production, Noveum.ai reveals:
- Peak usage occurs during business hours, causing latency spikes
- Certain question types consistently retrieve irrelevant documents
- Token usage is 30% higher than expected due to verbose context
Optimization Cycle
Based on these insights, you:
- Cache embeddings for common questions (reduces latency by 60%)
- Improve vector search by fine-tuning similarity thresholds
- Switch to GPT-3.5 for simple questions (reduces costs by 40%)
- Implement streaming for better user experience
Continuous Improvement
As your bot evolves:
- New conversation patterns are automatically captured
- Quality metrics help identify areas for improvement
- Cost trends inform capacity planning
- Error analysis guides bug fixes and feature development
Advanced Observability Patterns
Custom Metrics and Attributes
Noveum.ai allows you to add domain-specific insights:
@noveum_trace.trace("content-moderation")
def moderate_content(text: str, user_id: str):
# Add business context
noveum_trace.set_attribute("user.trust_level", get_user_trust_level(user_id))
noveum_trace.set_attribute("content.category", classify_content_type(text))
noveum_trace.set_attribute("moderation.policy_version", "v2.1")
# Perform moderation
result = run_content_moderation(text)
# Add results
noveum_trace.set_attribute("moderation.risk_score", result.risk_score)
noveum_trace.set_attribute("moderation.action_taken", result.action)
return result
Error Tracking and Alerting
Comprehensive error handling with actionable insights:
const processDocument = trace('document-processing', async (documentId: string) => {
try {
const result = await span('extract-text', async () => {
return await extractTextFromDocument(documentId);
});
return await span('analyze-content', async (spanInstance) => {
spanInstance.setAttribute('document.word_count', result.wordCount);
spanInstance.setAttribute('document.language', result.language);
return await analyzeContent(result.text);
});
} catch (error) {
// Rich error context for debugging
const currentSpan = getCurrentSpan();
currentSpan.setAttribute('error.type', error.constructor.name);
currentSpan.setAttribute('error.message', error.message);
currentSpan.setAttribute('error.recoverable', isRecoverableError(error));
currentSpan.setStatus('ERROR', error.message);
throw error;
}
});
The Future of AI Observability
What's Coming Next
As AI applications become more sophisticated, observability needs to evolve:
- 🤖 Agent Ecosystems: Observing complex multi-agent societies
- 🧠 Reasoning Chains: Tracing LLM thought processes
- 🔄 Feedback Loops: Connecting user outcomes back to traces
- 📊 Quality Metrics: Advanced measures of AI output quality
- 🛡️ Safety Monitoring: Detecting harmful or biased outputs
Building Observability-First AI Applications
The future belongs to teams who build observability into their AI applications from day one:
- Faster Debugging: Find and fix issues before they impact users
- Data-Driven Optimization: Make decisions based on real usage patterns
- Proactive Monitoring: Catch problems before they become incidents
- Continuous Improvement: Use traces to guide development priorities
Conclusion
The power of Noveum.ai lies in its comprehensive observability approach:
- 🚀 Easy Integration: Start tracing with minimal code changes
- 🔍 Deep Insights: Understand every aspect of your AI workflows
- 📊 Actionable Analytics: Make data-driven optimization decisions
- 🛠️ Developer-Friendly: Built by AI engineers, for AI engineers
Every API call, every embedding generation, every agent interaction becomes part of a bigger picture that helps you build better AI applications. Instead of guessing why something went wrong, you have concrete data and detailed traces to guide your decisions.
Whether you're debugging a complex RAG pipeline, optimizing multi-agent coordination, or simply trying to reduce your AI costs, Noveum.ai provides the visibility you need to succeed.
Ready to see your AI applications like never before? Start tracing today or talk to our team about your specific observability needs. We're here to help you build AI applications that are transparent, optimized, and reliable—one trace at a time.
Get Early Access to Noveum.ai Platform
Join the select group of AI teams optimizing their models with our data-driven platform. We're onboarding users in limited batches to ensure a premium experience.